



Fooocus AI ist eine grafische Oberfläche für Stable Diffusion, die einen einfachen Start auf dem eigenen Rechner erlaubt, aber auch für komplexere Aufgabenstellungen geeignet ist. Im Vergleich zu Midjourney oder Dall·E hat Stable Diffusion den Ruf, ein Werkzeug für Nerds zu sein – mit viel Flexibilität durch individuelle Konfiguration, aber auch mit gewissem Anspruch an die technische Expertise.
Fooocus tritt mit dem Anspruch an, das Potential von Stable Diffusion ähnlich einfach verfügbar zu machen wie Midjourney. Ob das in der Praxis tatsächlich klappt, haben wir uns mal genauer angeschaut.
Inhalte
Wer Stable Diffusion auf dem eigenen Rechner betreiben will, hat die Qual der Wahl zwischen verschiedenen grafischen Oberflächen. Die bekanntesten sind:
- Automatic1111 mit einer komplexen Oberfläche, mit der sich verschiedenste Anforderungen abdecken lassen
- ComfyUI, das auf grafischen Workflows basiert, mit denen man komplexe Prozesse abbilden kann.
Fooocus dagegen setzt auf einen einfachen Einstieg und positioniert sich als direkte Alternative zu Midjourney. Diesem Anspruch wird Fooocus durchaus gerecht:
- Beim ersten Blick minimales Interface mit Prompteingabe
- Schrittweise Darstellung weiterführender Optionen und Workflows bei Bedarf
Fooocus AI Download
Fooocus AI lässt sich einfach und kostenlos von Github runterladen. Die Fooocus Projekt Seite auf Github bietet neben dem eigentlichen Fooocus Download und entsprechenden Anleitungen auch einen Vergleich der vielen Funktionen zu ihren Midjourney Entsprechungen.
Fooocus AI Installation
Fooocus auf dem eigenen Rechner zu installieren, erfordert einige zusätzliche Schritte im Vergleich zur Installation eines normalen Programms. Man muss selber natürlich nicht programmieren können, aber auf der Befehlszeile („Eingabeaufforderung“ unter Windows, „Terminal“ auf dem Mac) einige Kommandos eingeben. Die Installation selber wird auf der Github-Seite des Projekts für alle relevanten Plattform (Win, Linux, Mac) und in vielen Varianten ausführlich und verständlich erklärt, so dass wir das an dieser Stelle überspringen.
Der erste Start
Hat man die Hürden der Installation genommen, wird das Programm auf der Befehlszeile gestartet, auf Windows / Eingabeaufforderung mit run.bat, auf dem Mac / Terminal mit python entry_with_update.py
Beim ersten Start werden die Stable Diffusion SDXL Modelle (ca. 6GB jeweils) runtergeladen, daher ist – abhängig von der Internetverbindung – etwas Geduld und Plattenplatz erforderlich. Anschließend startet ein lokaler Webserver und öffnet einen Browser mit der richtigen Startadresse, in der Regel unter http://127.0.0.1:7865
Die erste Ansicht ist schlicht:
- Leeres Bildfenster
- Leerer Prompt mit „Generate“ Button und
- Zwei Checkboxen „Input Image“ und „Advance“, die wir erstmal ignorieren, die aber gleich spannend werden
Extrem reduziert, aber zweckmäßig:
- Prompt eingeben
- „Generate“ klicken und…
- Das Bild wird generiert

Was gerade im Hintergrund passiert, wird neben dem Verlaufsbalken angezeigt: Das Text-Prompt wird verarbeitet, das Modell auf den Grafikprozessor verschoben und dann das Bild schrittweise generiert.
Fooocus AI Konfiguration, die erste…
Mit welchen Parameter der Prozess gestartet wurde, zeigt ein Klick auf die Checkbox „Advanced“: Rechts neben der Bildanzeige erscheint ein Panel, dessen erster Reiter „Setting“ grundlegende Einstellungen zeigt:
- Auswahl der Performance zwischen „Speed“, „Quality“ und „Extreme Speed“
- Unterschiedliche Auflösungen und ihre Seitenverhältnisse
- Schieberegler mit der Anzahl zu generierenden Bilder
- Texteingabefeld „Negative Prompt“
- Mit „Random“ beschriftete Checkbox, hinter der sich der Seed für die Bildgenerierung verbirgt.
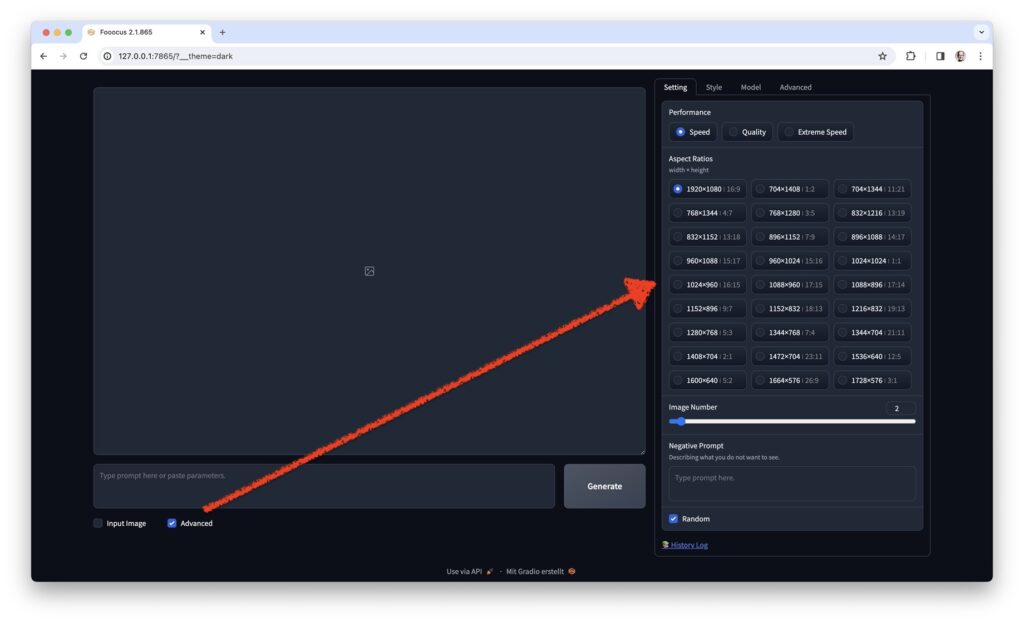
Die Parameter sind einigermaßen selbsterklärend für jeden, der sich mit KI-Bilder etwas auseinander gesetzt hat. Auf einige Details werden wir in weiteren Artikel noch eingehen, u.a. wie man eigene Auflösungen ergänzen kann oder eigene Standard-Werte setzt.
Fooocus Styles
Der nächste Reiter „Styles“ bietet über 200 verschiedene Stilrichtungen an. Dabei handelt es sich nicht – wie man denken könnte – um spezielle Modelle oder LoRAs (mehr dazu unten), sondern simple Prompt-Erweiterungen: Die User-Eingabe im Promptfeld wird erweitert, in einigen Stilen werden auch Negativ-Prompts ergänzt. Wenn man mit der Maus über die einzelnen Stile geht, wird ein mehr oder weniger aussagekräftiges Katzenbild eingeblendet, um einen ersten Eindruck des Stils zu geben. Hier einige Beispiele mit dem simplen Prompt „Cowboy“:




Model, Refiner und LoRAs
Mit jedem weiteren Reiter gehts weiter in die technischen Aspekte von Stable Diffusion: Im zweiten Reiter „Model“ lässt sich einstellen, welche Modelle für die Bildgenerierung eingesetzt werden sollen.
- Das Basismodell (auf SDXL beschränkt)
- Das Refiner-Modell, das für die Details zuständig ist
- Bis zu 5 LoRAs
Was LoRAs sind, werden wir in einem anderen Artikel erklären. In aller Kürze: LoRAs (LowRank Adaption) sind Ergänzungen, die den „großen“ Stable Diffusion Modellen „Spezialfähigkeiten“ antrainieren, um z.B. spezielle Charaktere oder Effekte zu generieren.

Advanced-Advanced und Developer Modus
Der letzte Reiter ist für Technik-affine, die spezielle Wünsche zum Fine-Tuning haben:
- Guidance Scale
- Image Sharpness
Noch weiter in den Stable Diffusion Techie-Kaninchenbau geht es hinter der Checkbox „Developer Debug Mode“…

Mächtige Tools: Bildvorgaben mit Fooocus
Nach dem tiefen Griff in den technischen Werkzeugkasten, sollten wir Blick auf die zweite Checkbox werfen, die unter dem Prompt sitzt: „Input Image“ öffnet einen neuen Satz Reiter unter dem Eingabefeld, in denen sich jeweils Bildvorlagen für folgende Workflows per Drag & Drop hochladen lassen.
Upscale or Variation
Erzeugt Variationen oder hochauflösende Varianten eines Bilds. Auf meinem Macbook M3 Pro konnte ich so Bilder mit 3.840 x 2.160 Pixeln generieren.
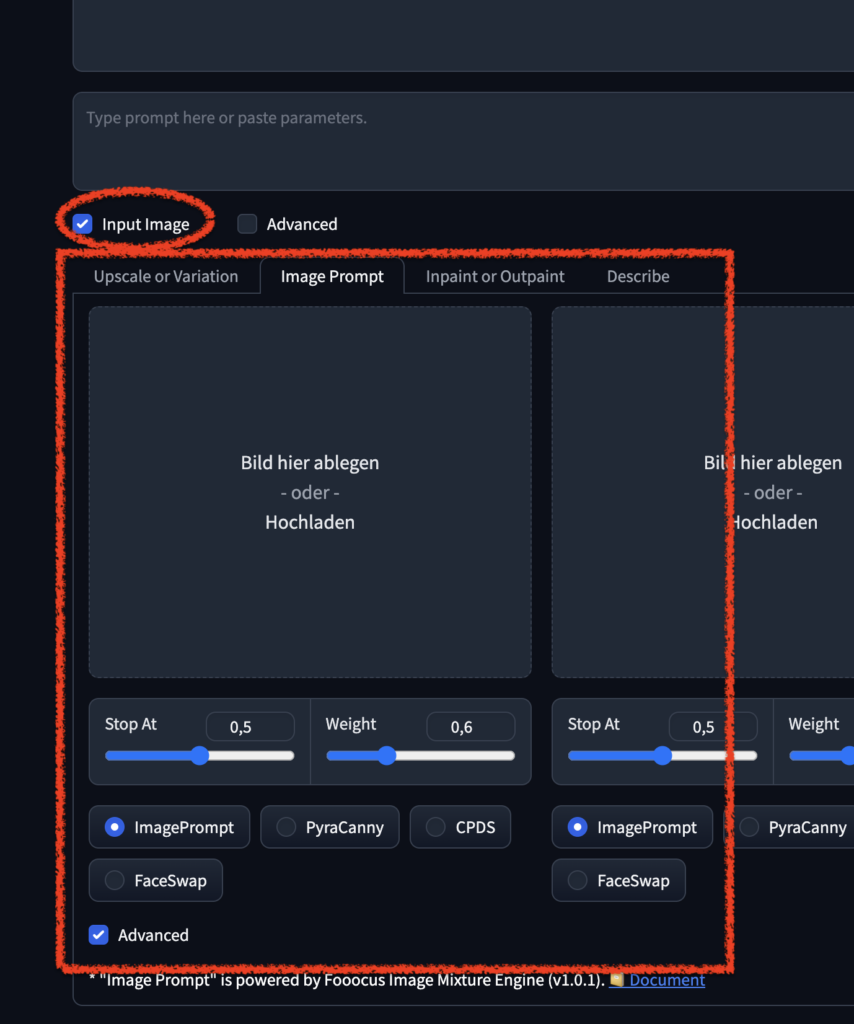
Image Prompt
Hier lassen sich bis zu vier Bilder hochladen, um sie als Vorlage zu verwenden. Auch hier gibt es noch einen Advanced Modus, in dem sich das Gewicht der Vorlage definieren lässt, vor allem aber auch, welcher Aspekt des Bildes übernommen werden soll:
- als ImagePrompt für den Stil
- via PyraCanny für Struktur des Bildes bzw. die Pose im Bild
- mit FaceSwap lässt sich das abgebildete Gesicht ins Zielbild übertragen



Inpaint or Outpaint
Die Optionen Inpainting und Outpainting erlauben es, das Bild in verschiedene Richtungen zu erweitern oder markierte Bildteile auszutauschen.



Describe
Liefert ein mögliches Prompt zu dem vorgegebenen Bild zurück (Image to Text). Diese Funktion gehört nicht zu den Stärken von Fooocus: Midjourney oder ChatGPT machen da einen deutlich besseren und ausführlicheren Job…
Zusammenfassung
So weit ein schneller Ritt durch die Oberfläche, der natürlich viele Themen nur streift oder ganz auslässt. Mein persönliches Fazit: Fooocus ist meine favorisierte Oberfläche für Stable Diffusion auf dem eigenen Rechner.
- Es bietet eine einfache und logisch strukturierte Oberfläche, die sich mit wenigen Klicks so erweitern lässt, dass sie den Griff in die Tiefen der Stable Diffusion Werkzeugkiste zulässt
- Der Bereich Input Image bietet mächtige Tools, um Bilder als Vorlagen zu verwenden (Image Prompt, Faceswap, PyraCanny)
- Hinzu kommen zahlreiche Funktionen, um effizienter zu arbeiten: Mit Platzhaltern können Prompts umfangreich variiert werden, Gewichtungen einzelner Begriffe können per Tastatur erfolgen, usw.
Konnte ich rüberbringen, was Fooocus so interessant macht? Freue mich über Kommentare und Fragen dazu!
Wenn du informiert werden willst, wenn wir Artikel zu Fooocus, Stable Diffusion oder anderen KI-Tools veröffentlichen, solltest du unseren Newsletter abonnieren.
FAQ Fooocus AI
Wo gibt es den Fooocus AI Download?
Auf Github gibt es hier den Fooocus Code und eine Anleitung, wie du Fooocus auf Windows, Linux oder auf dem Mac installierst.
Was kostet Fooocus AI?
Fooocus ist kostenlos.

{kind=link}