

_055d65.png)
_ee1da0.png)
Rangliste
-
adrianrohnfelder
Moderators78Punkte286Gesamte Inhalte -
Mattes
Mitglieder60Punkte89Gesamte Inhalte -

Zauberfrau
Mitglieder24Punkte53Gesamte Inhalte -
Andreas J.
Administrators21Punkte198Gesamte Inhalte




Beliebte Inhalte
Inhalte mit der höchsten Reputation seit 12.04.2023 in allen Bereichen anzeigen
-
4 Punkte4 PunkteIch habe mal wieder mit etwas ganz einfachem experimentiert und zwar mit dem Prompt MOTIV in the bottle, black background. Hat was 🙂






 3 PunkteSpannend finde ich auch, was herauskommt, wenn man Firefly einfach mal "machen lässt", also keine Vorgabe in den Prompt schreibt. Original: Drei "Vorschläge" aus Firefly:
3 PunkteSpannend finde ich auch, was herauskommt, wenn man Firefly einfach mal "machen lässt", also keine Vorgabe in den Prompt schreibt. Original: Drei "Vorschläge" aus Firefly:


 3 PunkteTop! Sieht sehr gut aus. Autos gehen auch mit SD. Aber bei den Umgebungsvariablen braucht es oft etliche Versuche. Ich suche mir meist einen passenden Promt bei civitai und verändere dann die mir wichtigen Variablen, wie (hier) Autotyp, Tageszeit, Gebäude, Umgebung allgemein... Die letzten beiden sollten Plymouth Fury werden, zu Mittag in einer Staubwüste...
3 PunkteTop! Sieht sehr gut aus. Autos gehen auch mit SD. Aber bei den Umgebungsvariablen braucht es oft etliche Versuche. Ich suche mir meist einen passenden Promt bei civitai und verändere dann die mir wichtigen Variablen, wie (hier) Autotyp, Tageszeit, Gebäude, Umgebung allgemein... Die letzten beiden sollten Plymouth Fury werden, zu Mittag in einer Staubwüste...

 3 PunkteNatürlich musste ich die Integration von Adobe Firefly in Adobe Photoshop gleich einmal ausprobieren 🙂 Aktuell funktioniert das nur in der Desktop Beta-Version von Photoshop. Die findet Ihr in der Creative Cloud unter den Beta-Applikationen und könnt sie von dort aus parallel zu der 'normalen' Photoshop Version zusätzlich installieren. In der Photoshop Beta öffnet Ihr Euer Bild und markiert mit einem Auswahlwerkzeug den Bereich, dem Ihr etwas hinzufügen möchtet. Es erscheint automatisch ein Kontextmenü in welches Ihr (auf Englisch) eingeben könnt, was dem Bereich hinzugefügt werden soll wie z.B. "add a dinosaur". Anschließend drückt Ihr auf 'Generieren', wartet kurz (oder länger je nach Rechner) und erhaltet dann drei alternative Motive vorgeschlagen. Ihr müsst dabei mit dem Internet verbunden sein, da die Funktion 'Generative Füllung' eine Cloud-Verarbeitung erfordert. Das geht super einfach und macht richtig Spaß. Allerdings sind die Ergebnisse sehr durchwachsen. Manchmal funktioniert es super, manche Motive sind einfach nur gruselig (da ist Midjourney in der Qualität noch um Welten besser als Adobe Firefly). Manchmal passen die Schatten und das Licht, manchmal gar nicht. Auch die Größenverhältnisse und Perspektiven machen nicht immer Sinn. Grundsätzlich zeigt die Beta-Version jedoch das enorme Potential und könnte in der Tat ein echter Gamechanger werden.
3 PunkteNatürlich musste ich die Integration von Adobe Firefly in Adobe Photoshop gleich einmal ausprobieren 🙂 Aktuell funktioniert das nur in der Desktop Beta-Version von Photoshop. Die findet Ihr in der Creative Cloud unter den Beta-Applikationen und könnt sie von dort aus parallel zu der 'normalen' Photoshop Version zusätzlich installieren. In der Photoshop Beta öffnet Ihr Euer Bild und markiert mit einem Auswahlwerkzeug den Bereich, dem Ihr etwas hinzufügen möchtet. Es erscheint automatisch ein Kontextmenü in welches Ihr (auf Englisch) eingeben könnt, was dem Bereich hinzugefügt werden soll wie z.B. "add a dinosaur". Anschließend drückt Ihr auf 'Generieren', wartet kurz (oder länger je nach Rechner) und erhaltet dann drei alternative Motive vorgeschlagen. Ihr müsst dabei mit dem Internet verbunden sein, da die Funktion 'Generative Füllung' eine Cloud-Verarbeitung erfordert. Das geht super einfach und macht richtig Spaß. Allerdings sind die Ergebnisse sehr durchwachsen. Manchmal funktioniert es super, manche Motive sind einfach nur gruselig (da ist Midjourney in der Qualität noch um Welten besser als Adobe Firefly). Manchmal passen die Schatten und das Licht, manchmal gar nicht. Auch die Größenverhältnisse und Perspektiven machen nicht immer Sinn. Grundsätzlich zeigt die Beta-Version jedoch das enorme Potential und könnte in der Tat ein echter Gamechanger werden.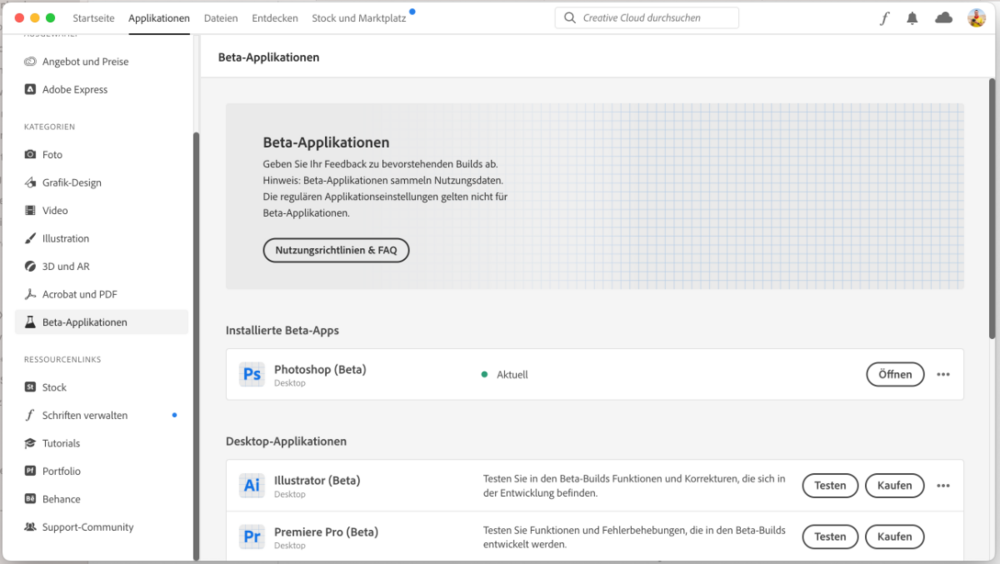



 2 Punkte2 PunkteHallo. Gestern hat Leonardo.AI im Rahmen eines größeres Updates SDXL 0.9 und Prompt Magic 3.0 ergänzt. Nach meiner Einschätzung ist das nochmals ein deutlicher Sprung nach vorn. Hier mal ein paar Beispiele:
2 Punkte2 PunkteHallo. Gestern hat Leonardo.AI im Rahmen eines größeres Updates SDXL 0.9 und Prompt Magic 3.0 ergänzt. Nach meiner Einschätzung ist das nochmals ein deutlicher Sprung nach vorn. Hier mal ein paar Beispiele:
 2 Punkte2 PunkteIch bin immer noch beeindruckt. Und immer noch ein wenig erschrocken…
2 Punkte2 PunkteIch bin immer noch beeindruckt. Und immer noch ein wenig erschrocken…

 2 Punkte2 PunkteWenn du mit der Gallerie die MJ-App meinst, wo man alle seine Bilder ohne Discord sieht: Stimmt, die ist großer Mist. Noch! Sie soll wohl recht mächtig werden, sodass man sogar dort ohne Discord seine Bilder generieren kann. Allerdings ist das Ding wohl noch lange nicht so weit und die zu Verfügung stehenden Funktionen wie das Verwalten der Bilder sind mau. Aber es gibt die Möglichkeit, die alte Gallerie wieder aus der Gruft zu holen: https://legacy.midjourney.com/app/ Da isse. ☺️ Hat mich auch geärgert. Auf dem MJ-Discord-Server kann im Kanal # web-feedback munter darüber diskutiert werden. Hier wirst du jede Menge Gleichgesinnte finden. 😉2 Punkte2 PunkteHallo Zusammen, ich bin Hobbyfotograf und bisher ein absoluter Rookie in Sachen AI Art. Gestern habe ich Leonardo AI für mich entdeckt und seitdem viel ausprobiert. Gerade habe ich dieses Forum entdeckt und mich sofort angemeldet. 🙂 Hier mal einige Beispiele meiner bisherigen Bilder. Allesamt Photo real. Bin mit den Ergebnissen bis auf ein paar Details sehr zufrieden für den Anfang. Was sagt ihr?
2 Punkte2 PunkteWenn du mit der Gallerie die MJ-App meinst, wo man alle seine Bilder ohne Discord sieht: Stimmt, die ist großer Mist. Noch! Sie soll wohl recht mächtig werden, sodass man sogar dort ohne Discord seine Bilder generieren kann. Allerdings ist das Ding wohl noch lange nicht so weit und die zu Verfügung stehenden Funktionen wie das Verwalten der Bilder sind mau. Aber es gibt die Möglichkeit, die alte Gallerie wieder aus der Gruft zu holen: https://legacy.midjourney.com/app/ Da isse. ☺️ Hat mich auch geärgert. Auf dem MJ-Discord-Server kann im Kanal # web-feedback munter darüber diskutiert werden. Hier wirst du jede Menge Gleichgesinnte finden. 😉2 Punkte2 PunkteHallo Zusammen, ich bin Hobbyfotograf und bisher ein absoluter Rookie in Sachen AI Art. Gestern habe ich Leonardo AI für mich entdeckt und seitdem viel ausprobiert. Gerade habe ich dieses Forum entdeckt und mich sofort angemeldet. 🙂 Hier mal einige Beispiele meiner bisherigen Bilder. Allesamt Photo real. Bin mit den Ergebnissen bis auf ein paar Details sehr zufrieden für den Anfang. Was sagt ihr?


 2 Punkte2 PunkteLicht und Farbe lagen an meinem Prompt, ich wollte auf eine "Cyberpunk"-Atmosphäre hinaus. Es geht aber auch ganz anders:
2 Punkte2 PunkteLicht und Farbe lagen an meinem Prompt, ich wollte auf eine "Cyberpunk"-Atmosphäre hinaus. Es geht aber auch ganz anders: 2 Punkte2 Punkte2 Punkte2 PunkteHallo, ich habe mich heute erst hier registriert und hier sind einige Sachen aus meinen ersten Tagen bei Leo A.I. von vor Monaten bis heute. Nicht alles ist gut, vieles nicht geupscaled, aber so in etwa sieht meine Scifi Welt aus. Dies ist nur ein kleiner Ausschnitt. Vieles ist brauchbar und dient eher als Motivation/Inspiration.
2 Punkte2 Punkte2 Punkte2 PunkteHallo, ich habe mich heute erst hier registriert und hier sind einige Sachen aus meinen ersten Tagen bei Leo A.I. von vor Monaten bis heute. Nicht alles ist gut, vieles nicht geupscaled, aber so in etwa sieht meine Scifi Welt aus. Dies ist nur ein kleiner Ausschnitt. Vieles ist brauchbar und dient eher als Motivation/Inspiration.





.thumb.jpg.3693ddc8c13a552c1f34b01d0ed214ab.jpg)

















 2 PunkteIst vielleicht Eulen nach Athen getragen. Aber ich habe zwei ganz interessante Tutorials in deutscher Sprache auf Youtube gefunden. Midjourney-Tutorial auf Deutsch für Anfänger (Youtube) Dieses Tutorial startet tatsächlich bei Null (Anmeldung bei Discord, Midjourney usw.). Allerdings finde ich am Ende viele Infos sehr cool, die ich selbst noch nicht wusste. Zum Beispiel wurde auf zwei interessante Webseiten verwiesen, womit man das Prompting besser gestalten kann. Ohne die beiden Links jetzt selbst schon getestet zu haben sind das: Midlibrary.IO (Webeseiten-Link) Das scheint eine Art Bibliothek zu sein, wo man sich schlau machen kann, welcher Prompt welchen Stil hervorbringt. Mit über 3000 Beispielbildern. (noch ungetestet) Prompt.Noonshot.com (Webseiten-Link) Ist zwar für Version 4, fest eingestellt, man kann aber seinen Prompt damit erstellen und nach dem Kopieren auf Discord gerade das "--v 4" dahinter löschen, wenn man das nicht will. Ansonsten scheint es ganz gut zu sein, sich einen Prompt mit entsprechendem Licht usw. zusammenzuklickern. (wie gesagt, noch ungetestet) Dann habe ich mir noch für alle Anime- und Manga-Fans dieses Youtube-Tutorial gegönnt: Anime AI Art Guide (Youtube) Ist eine schnelle Zusammenfassung, was mit dem --niji - Parameter bei Midjourney alles möglich ist. Bin zwar jetzt nicht so im Niji-Umfeld zuhause, fand das aber recht interessant. Vielleicht ist für den ein oder anderen was Brauchbares dabei. Ich wollte es hier nicht unerwähnt lassen. 😊 Viele Grüße von der Zauberfrau2 Punkte2 PunkteDie Kombination aus "Prompt Magic v3.0" und "Photoreal" kann was:
2 PunkteIst vielleicht Eulen nach Athen getragen. Aber ich habe zwei ganz interessante Tutorials in deutscher Sprache auf Youtube gefunden. Midjourney-Tutorial auf Deutsch für Anfänger (Youtube) Dieses Tutorial startet tatsächlich bei Null (Anmeldung bei Discord, Midjourney usw.). Allerdings finde ich am Ende viele Infos sehr cool, die ich selbst noch nicht wusste. Zum Beispiel wurde auf zwei interessante Webseiten verwiesen, womit man das Prompting besser gestalten kann. Ohne die beiden Links jetzt selbst schon getestet zu haben sind das: Midlibrary.IO (Webeseiten-Link) Das scheint eine Art Bibliothek zu sein, wo man sich schlau machen kann, welcher Prompt welchen Stil hervorbringt. Mit über 3000 Beispielbildern. (noch ungetestet) Prompt.Noonshot.com (Webseiten-Link) Ist zwar für Version 4, fest eingestellt, man kann aber seinen Prompt damit erstellen und nach dem Kopieren auf Discord gerade das "--v 4" dahinter löschen, wenn man das nicht will. Ansonsten scheint es ganz gut zu sein, sich einen Prompt mit entsprechendem Licht usw. zusammenzuklickern. (wie gesagt, noch ungetestet) Dann habe ich mir noch für alle Anime- und Manga-Fans dieses Youtube-Tutorial gegönnt: Anime AI Art Guide (Youtube) Ist eine schnelle Zusammenfassung, was mit dem --niji - Parameter bei Midjourney alles möglich ist. Bin zwar jetzt nicht so im Niji-Umfeld zuhause, fand das aber recht interessant. Vielleicht ist für den ein oder anderen was Brauchbares dabei. Ich wollte es hier nicht unerwähnt lassen. 😊 Viele Grüße von der Zauberfrau2 Punkte2 PunkteDie Kombination aus "Prompt Magic v3.0" und "Photoreal" kann was: 2 PunkteSuperdog 😅2 Punkte2 PunkteHallo, ich bin der Spanksen (Murat) - freut mich ein Teil der AI Community sein zu dürfen. Im Moment reizt es mich gerade mit Generative Fill alten Bildern von mir neues Leben einzuhauchen und eine Story zu erzählen die vorher nicht da war oder die ich im Kopf hatte aber nicht umsetzten konnte. Die alten Bilder inspirieren mich grade dadurch komplett neu. Hier mal ein paar Beispiele Hier zum Beispiel das große Problem des Drogen- und Tablettenmissbrauchs (Oxys, Benzos etc.) was wir auf Sylt mit sehr vielen Jugendlichen auf Sylt (und nicht nur hier natürlich) haben sowie die Perspektivlosigkeit im starken Kontrast zur Schönheit der Insel.2 PunkteDie Stimmung in einem verschneiten Wald ist gut getroffen, finde ich:
2 PunkteSuperdog 😅2 Punkte2 PunkteHallo, ich bin der Spanksen (Murat) - freut mich ein Teil der AI Community sein zu dürfen. Im Moment reizt es mich gerade mit Generative Fill alten Bildern von mir neues Leben einzuhauchen und eine Story zu erzählen die vorher nicht da war oder die ich im Kopf hatte aber nicht umsetzten konnte. Die alten Bilder inspirieren mich grade dadurch komplett neu. Hier mal ein paar Beispiele Hier zum Beispiel das große Problem des Drogen- und Tablettenmissbrauchs (Oxys, Benzos etc.) was wir auf Sylt mit sehr vielen Jugendlichen auf Sylt (und nicht nur hier natürlich) haben sowie die Perspektivlosigkeit im starken Kontrast zur Schönheit der Insel.2 PunkteDie Stimmung in einem verschneiten Wald ist gut getroffen, finde ich:



 2 Punkte2 PunkteSehr sehr cool, also Bilder und Geschichte. Du kennst doch sicher die Bücher "His Dark Materials" wo die Personen einen Dämonen in Form eines Tieres haben. Daran musste ich sofort bei dem Waschbär denken.2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 PunkteKleine Spielerei zwischendurch mit dem Prompt [FILMTITEL] isometric cube micro world underground cut away Wer kann die Filme zuordnen: Alien, Westworld, Mad Max, Ready Player One, Pirates of the Carribean, Blade Runner, Interstellar, Harry Potter, Star Wars Mustafar, Star Wars Tatooine, Indiana Jones, Mordor Herr der Ringe? Jetzt dürft Ihr 😉
2 Punkte2 PunkteSehr sehr cool, also Bilder und Geschichte. Du kennst doch sicher die Bücher "His Dark Materials" wo die Personen einen Dämonen in Form eines Tieres haben. Daran musste ich sofort bei dem Waschbär denken.2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 PunkteKleine Spielerei zwischendurch mit dem Prompt [FILMTITEL] isometric cube micro world underground cut away Wer kann die Filme zuordnen: Alien, Westworld, Mad Max, Ready Player One, Pirates of the Carribean, Blade Runner, Interstellar, Harry Potter, Star Wars Mustafar, Star Wars Tatooine, Indiana Jones, Mordor Herr der Ringe? Jetzt dürft Ihr 😉










 2 PunkteJa, genau hier ist der Ansatz. Wir müssen damit umgehen lernen, wie mit dem Telefon (war vor gut 100 Jahren angeblich eine riesige Diskussion, ob das Telefon nicht entmenschlicht), dem Handy oder dem Internet.2 PunkteDarum habe ich ja auch "lasse ich mich von Chat GPT unterstützen" geschrieben. Es ist super, um mal eine Idee zu bekommen oder etwas auszuschmücken, mit Sparringspartner beschreibst Du das sehr gut. Ähnlich würde ich auch die Bilder von Storybird sehen, als eine Idee oder Alternative, die man selbst so nicht im Kopf hatte. Wie geschrieben, ich schaue mir das zumindest einmal an.2 Punkte2 PunkteYep, das ist echt unglaublich wie gut insbesondere das Erweitern von Fotos funktioniert, der rote Rahmen zeigt das originale Bild.
2 PunkteJa, genau hier ist der Ansatz. Wir müssen damit umgehen lernen, wie mit dem Telefon (war vor gut 100 Jahren angeblich eine riesige Diskussion, ob das Telefon nicht entmenschlicht), dem Handy oder dem Internet.2 PunkteDarum habe ich ja auch "lasse ich mich von Chat GPT unterstützen" geschrieben. Es ist super, um mal eine Idee zu bekommen oder etwas auszuschmücken, mit Sparringspartner beschreibst Du das sehr gut. Ähnlich würde ich auch die Bilder von Storybird sehen, als eine Idee oder Alternative, die man selbst so nicht im Kopf hatte. Wie geschrieben, ich schaue mir das zumindest einmal an.2 Punkte2 PunkteYep, das ist echt unglaublich wie gut insbesondere das Erweitern von Fotos funktioniert, der rote Rahmen zeigt das originale Bild.
 2 PunkteAber die Herr der Ringe Bücher hat es gelesen 🙂
2 PunkteAber die Herr der Ringe Bücher hat es gelesen 🙂 2 Punkte2 PunkteEine Möglichkeit wäre es zudem, dass Du Dir jeweils ein Graffiti für jeden einzelnen Buchstaben generieren lässt, das sollte funktionieren. Und dann alle Buchstaben in z.B. Photoshop zu einem Graffiti zusammenbaust. Dazu nutzt Du am besten bei jedem Bild den gleichen --seed. Aber klar, ist deutlich aufwendiger.2 Punkte2 PunkteHier mal noch zwei Ergebnisse von heute. Bis auf die Augen schon sehr ansehnlich finde ich. Und Supergirl darf nicht fehlen 😄
2 Punkte2 PunkteEine Möglichkeit wäre es zudem, dass Du Dir jeweils ein Graffiti für jeden einzelnen Buchstaben generieren lässt, das sollte funktionieren. Und dann alle Buchstaben in z.B. Photoshop zu einem Graffiti zusammenbaust. Dazu nutzt Du am besten bei jedem Bild den gleichen --seed. Aber klar, ist deutlich aufwendiger.2 Punkte2 PunkteHier mal noch zwei Ergebnisse von heute. Bis auf die Augen schon sehr ansehnlich finde ich. Und Supergirl darf nicht fehlen 😄
 2 Punkte2 PunkteHallo. Meine ersten Gehversuche habe ich mit Leonardo.AI gemacht. Hier möchte ich Euch einige meiner Portraits zeigen und lade jeden herzlich ein, sich mit seinen Bildern zu beteiligen... Viele Grüße Mattes
2 Punkte2 PunkteHallo. Meine ersten Gehversuche habe ich mit Leonardo.AI gemacht. Hier möchte ich Euch einige meiner Portraits zeigen und lade jeden herzlich ein, sich mit seinen Bildern zu beteiligen... Viele Grüße Mattes

 2 PunkteHallo. Midjourney bekommt nach meinen Tests Fahrzeuge besser hin, aber Leonardo ist auch nicht so schlecht: Grüße Matthias
2 PunkteHallo. Midjourney bekommt nach meinen Tests Fahrzeuge besser hin, aber Leonardo ist auch nicht so schlecht: Grüße Matthias

 2 Punkte2 PunkteMidjourney habe ich schon getestet bevor es dann kostenpflichtig wurde. Aktuell habe ich außer "rumspielen" noch keine Verwendung für die Bilder und daher auch keinen kostenpflichtigen Account. Prompt von der Dame mit Katze war: Und die sitzende Dame: Zusammenfassend kann man sagen bei 10 Bildern kommt 2-3 mal was richtig übles raus, 1 mal was richtig gutes und der Rest ist brauchbar. Meine besten Bilder kann ich hier nicht zeigen, da ich auch ein wenig mit NSFW Content herumgespielt habe wenn das ganze schon unzensiert ist 😄 Was ich interessant finde ist, dass die freien Varianten so schnell aufholen. Und das kann fast jeder mit nem halbwegs guten Rechner erstellen (Bei meinem betagten Ryzen 7 2700X mit Geforce 1080ti dauert ein Bild hochskaliert auf 1024*1024 ca 30-40s). Auf meinem M1 Macbook gehts etwas langsamer aber auch problemlos. Das Modell ist grade mal 2GB groß und das Programm an sich 6GB. Also Peanuts. Da steckt echt ne pfiffige Community dahinter. Wenn das so weitergeht können sich die etablierten kostenpflichtigen bald warm anziehen.2 Punkte2 PunkteIch habe nun einiges mit Stable Diffusion aus meinem Link oben experimentiert. Wichtig ist das Model das man dazu nutzt. Ich habe viel mit dem "analog Madness" von civitai.com herumprobiert nun. Da kommen teils schon sehr gute Ergebnisse raus, teils auch ziemlicher Mist vor allem wenn man etwas komplexere Dinge haben will wie hier z.B. Die Dame sollte doch nur eine Katze auf der Schulter haben aber stattdessen hat sie noch einen Katzenpelz und Katzenohren bekommen sowie eine verunstaltete Katze im Hintergrund 😄 Wenns dann nur eine Frau sein soll geht das schon besser:
2 Punkte2 PunkteMidjourney habe ich schon getestet bevor es dann kostenpflichtig wurde. Aktuell habe ich außer "rumspielen" noch keine Verwendung für die Bilder und daher auch keinen kostenpflichtigen Account. Prompt von der Dame mit Katze war: Und die sitzende Dame: Zusammenfassend kann man sagen bei 10 Bildern kommt 2-3 mal was richtig übles raus, 1 mal was richtig gutes und der Rest ist brauchbar. Meine besten Bilder kann ich hier nicht zeigen, da ich auch ein wenig mit NSFW Content herumgespielt habe wenn das ganze schon unzensiert ist 😄 Was ich interessant finde ist, dass die freien Varianten so schnell aufholen. Und das kann fast jeder mit nem halbwegs guten Rechner erstellen (Bei meinem betagten Ryzen 7 2700X mit Geforce 1080ti dauert ein Bild hochskaliert auf 1024*1024 ca 30-40s). Auf meinem M1 Macbook gehts etwas langsamer aber auch problemlos. Das Modell ist grade mal 2GB groß und das Programm an sich 6GB. Also Peanuts. Da steckt echt ne pfiffige Community dahinter. Wenn das so weitergeht können sich die etablierten kostenpflichtigen bald warm anziehen.2 Punkte2 PunkteIch habe nun einiges mit Stable Diffusion aus meinem Link oben experimentiert. Wichtig ist das Model das man dazu nutzt. Ich habe viel mit dem "analog Madness" von civitai.com herumprobiert nun. Da kommen teils schon sehr gute Ergebnisse raus, teils auch ziemlicher Mist vor allem wenn man etwas komplexere Dinge haben will wie hier z.B. Die Dame sollte doch nur eine Katze auf der Schulter haben aber stattdessen hat sie noch einen Katzenpelz und Katzenohren bekommen sowie eine verunstaltete Katze im Hintergrund 😄 Wenns dann nur eine Frau sein soll geht das schon besser:
 2 PunkteIch habe im Prompt "faded Kodachrome colors" angegeben, das funktioniert ziemlich gut. Ohne das "faded" (also etwa: "verblasst") sind mir die Farben zu kräftig. Das geht dann auch, sieht aber mehr nach Eggleston aus, als ich es hier haben wollte.2 PunkteHabe ich die Tage auch mal wieder ausprobiert. Die Ergebnisse sind in der Tat nicht verkehrt. Ich bevorzuge immer noch Midjourney, aber die Bing/ Dall-E Ergebnisse sind durchaus brauchbar.
2 PunkteIch habe im Prompt "faded Kodachrome colors" angegeben, das funktioniert ziemlich gut. Ohne das "faded" (also etwa: "verblasst") sind mir die Farben zu kräftig. Das geht dann auch, sieht aber mehr nach Eggleston aus, als ich es hier haben wollte.2 PunkteHabe ich die Tage auch mal wieder ausprobiert. Die Ergebnisse sind in der Tat nicht verkehrt. Ich bevorzuge immer noch Midjourney, aber die Bing/ Dall-E Ergebnisse sind durchaus brauchbar.
 2 PunkteMit SD habe ich leider noch nicht wirklich gearbeitet, ich meine aber @aicatcher bereits? Ansonsten habe ich ohne Ahnung zu haben 🙂 quick&dirty dieses Video gefunden, ist es das was Du suchst? https://www.youtube.com/watch?v=YSqQ67Z0U5U2 Punkte2 PunkteLetzter Test für heute: Drachen. Dieses Motiv ist für mich eine der größten Herausforderungen, die Physiognomie hat bisher so gut wie nie funktioniert. Prompt: dangerous malevolent fire breathing dragon, full body, with glowing eyes and large leathery wings and sharp talons fights against an large army of heavily-armored dwarves in the region of Mordor, flames, debris, scene of desctruction, dramatic light, cinematic lighting v5 v5.1 v5.1 --style raw Also hier hat v5.1 eindeutige Fortschritte gemacht! Auch die Zwergenarmee hat in v5.1 immerhin einmal funktioniert. Wenn jetzt auch noch das Feuer spucken klappen würde 🤪, aber gut, v5.2 und v6 dürfen ja auch noch Raum für Verbesserungen haben 🙂
2 PunkteMit SD habe ich leider noch nicht wirklich gearbeitet, ich meine aber @aicatcher bereits? Ansonsten habe ich ohne Ahnung zu haben 🙂 quick&dirty dieses Video gefunden, ist es das was Du suchst? https://www.youtube.com/watch?v=YSqQ67Z0U5U2 Punkte2 PunkteLetzter Test für heute: Drachen. Dieses Motiv ist für mich eine der größten Herausforderungen, die Physiognomie hat bisher so gut wie nie funktioniert. Prompt: dangerous malevolent fire breathing dragon, full body, with glowing eyes and large leathery wings and sharp talons fights against an large army of heavily-armored dwarves in the region of Mordor, flames, debris, scene of desctruction, dramatic light, cinematic lighting v5 v5.1 v5.1 --style raw Also hier hat v5.1 eindeutige Fortschritte gemacht! Auch die Zwergenarmee hat in v5.1 immerhin einmal funktioniert. Wenn jetzt auch noch das Feuer spucken klappen würde 🤪, aber gut, v5.2 und v6 dürfen ja auch noch Raum für Verbesserungen haben 🙂

 2 PunkteDa gehe ich mit. Die klassischen Tiles bei Etsy und co sind seit midjourney tile release ziemlich stark gesunken. Ich versuche gerade etwas modulares für die Dungeons & Dragons Gemeinde aufzubauen, mal schauen ob das funktioniert. So ein Unterforum wäre stark.2 Punkte2 PunkteEinfach unfassbar wie schnell wir uns mittlerweile in Richtung lebensechte Fotos bewegen. Klar sieht man es hier und da noch an Details (Augen, Gesichtsformen usw) aber wenn man bedenkt, dass wir erst in einem Jahr Entwicklung sind, ist es fast schon unfassbar. Hier mal meine Bilder:
2 PunkteDa gehe ich mit. Die klassischen Tiles bei Etsy und co sind seit midjourney tile release ziemlich stark gesunken. Ich versuche gerade etwas modulares für die Dungeons & Dragons Gemeinde aufzubauen, mal schauen ob das funktioniert. So ein Unterforum wäre stark.2 Punkte2 PunkteEinfach unfassbar wie schnell wir uns mittlerweile in Richtung lebensechte Fotos bewegen. Klar sieht man es hier und da noch an Details (Augen, Gesichtsformen usw) aber wenn man bedenkt, dass wir erst in einem Jahr Entwicklung sind, ist es fast schon unfassbar. Hier mal meine Bilder:
 2 Punkte1 PunktKennt Ihr schon Stability Matrix? Das ist eine kostenlose Desktop-App, welche die Installation von Stable Diffusion Web UIs wie Automatic1111, Comfy UI, VoltaML, InvokeAI und weitere vereinfacht:1 Punkt1 PunktHallo. Ein paar Spielereien aus Leonardo.AI. Ich finde, die Stimmung bestimmter Science-Fiction-Filme ist gut eingefangen. Grüße Mattes
2 Punkte1 PunktKennt Ihr schon Stability Matrix? Das ist eine kostenlose Desktop-App, welche die Installation von Stable Diffusion Web UIs wie Automatic1111, Comfy UI, VoltaML, InvokeAI und weitere vereinfacht:1 Punkt1 PunktHallo. Ein paar Spielereien aus Leonardo.AI. Ich finde, die Stimmung bestimmter Science-Fiction-Filme ist gut eingefangen. Grüße Mattes


 1 PunktGenau, die Basis sind reale Videos gemischt mit KI Bildern und Videos. Wie Du schreibst, das ist eine prima Inspiration!1 PunktBoah, echt schwierig, mit viel ausprobieren bzw. der Hilfe von Chat GPT habe ich einen langen Prompt gebastelt, welcher einigermaßen funktioniert. Noch nicht sehr 1920 like, aber immerhin mit Personen im Auto 🙂 A young man is driving an classic convertible car in 1920s Berlin. In the center of the image, there is a classic, early 20th-century automobile, black with a polished sheen that glistens in the afternoon sun. The car is a fully restored vintage model from the 1920s, complete with narrow running boards, large, spoked wheels, and rounded fenders. The convertible top is folded down, revealing the pristine interior, upholstered in a rich, warm brown leather. The large headlights at the front gleam, appearing almost oversized for the body of the car. Behind the wheel is a young man, smartly dressed in the fashion of the 1920s. He wears a dark brown suit, complete with a waistcoat, tie, and a crisp white shirt. His hair is slicked back neatly, and he has a pair of round spectacles perched on his nose. He holds a driving cap in one hand, waving it in the air as his other hand firmly grips the wooden steering wheel. The look on his face is one of pure joy, as though he's living the best moment of his life. The backdrop of the scene is the bustling city of Berlin in the 1920s. The cobblestone streets are busy with pedestrians and old vintage cars. To the right, there are towering buildings of stone and brick, with ornate facades and large glass windows. To the left, there's a park with people leisurely strolling, children playing, and the distant laughter echoing in the air.
1 PunktGenau, die Basis sind reale Videos gemischt mit KI Bildern und Videos. Wie Du schreibst, das ist eine prima Inspiration!1 PunktBoah, echt schwierig, mit viel ausprobieren bzw. der Hilfe von Chat GPT habe ich einen langen Prompt gebastelt, welcher einigermaßen funktioniert. Noch nicht sehr 1920 like, aber immerhin mit Personen im Auto 🙂 A young man is driving an classic convertible car in 1920s Berlin. In the center of the image, there is a classic, early 20th-century automobile, black with a polished sheen that glistens in the afternoon sun. The car is a fully restored vintage model from the 1920s, complete with narrow running boards, large, spoked wheels, and rounded fenders. The convertible top is folded down, revealing the pristine interior, upholstered in a rich, warm brown leather. The large headlights at the front gleam, appearing almost oversized for the body of the car. Behind the wheel is a young man, smartly dressed in the fashion of the 1920s. He wears a dark brown suit, complete with a waistcoat, tie, and a crisp white shirt. His hair is slicked back neatly, and he has a pair of round spectacles perched on his nose. He holds a driving cap in one hand, waving it in the air as his other hand firmly grips the wooden steering wheel. The look on his face is one of pure joy, as though he's living the best moment of his life. The backdrop of the scene is the bustling city of Berlin in the 1920s. The cobblestone streets are busy with pedestrians and old vintage cars. To the right, there are towering buildings of stone and brick, with ornate facades and large glass windows. To the left, there's a park with people leisurely strolling, children playing, and the distant laughter echoing in the air.
 1 PunktStability AI, das Unternehmen u.a. hinter Stable Diffusion hat mit dem Stable Animation SDK ein KI-Tool vorgestellt, mit dem sich Animationen erstellen lassen. Es stehen drei verschiedene Wege zur Verfügung: Via Text-Prompt: Aus einer Texteingabe mit verschiedenen Parametern erstellt Stable Animation eine Animation. Bild und Text-Prompt: Aus einem Ausgangsbild und einer Texteingabe wird die Animation generiert Video und Text-Prompt: Aus einem Video, das z.B. Bewegungsabläufe vorgibt und einer Texteingabe entsteht das Video. Um das SDK zu nutzen, muss auf dem eigenen Rechner das SDK installiert werden, eine ausführliche Dokumentation findet sich in der Dokumentation. Das parallel veröffentlichte Video zeigt anhand von Beispielen, welche Ergebnisse man erzielen kann: Die Kosten für die Nutzung der API werden auf einer eigenen Seite dokumentiert, sie hängen von Auflösung, Länge und Bildfrequenz der Animation ab. Die Pressemitteiung auf deutsch: Stability AI veröffentlicht Stable Animation SDK, ein leistungsstarkes Text-zu-Animationstool für Entwickler 11. Mai – Stability AI, das weltweit führende Open-Source-Unternehmen für künstliche Intelligenz, veröffentlicht heute das Stable Animation SDK, ein Tool für Künstler und Entwickler, mit dem sie die fortschrittlichsten Stable Diffusion-Modelle implementieren können, um beeindruckende Animationen zu erstellen. Benutzer können Animationen auf verschiedene Arten erstellen: durch Eingabeaufforderungen (ohne Bilder), ein Quellbild oder ein Quellvideo. Mit dem Stability AI-Animationsendpunkt können Künstler alle Stable Diffusion-Modelle, einschließlich Stable Diffusion 2.0 und Stable Diffusion XL, zur Erstellung von Animationen verwenden. Wir bieten drei Möglichkeiten zur Erstellung von Animationen: Text zu Animation: Die Benutzer geben eine Texteingabe ein (wie bei Stable Diffusion) und ändern verschiedene Parameter, um eine Animation zu erstellen. Texteingabe + Eingabe eines Ausgangsbildes: Die Benutzer geben ein Ausgangsbild ein, das als Startpunkt ihrer Animation dient. Eine Texteingabe wird in Verbindung mit dem Bild verwendet, um die endgültige Animation zu erzeugen. Videoeingabe + Texteingabe: Die Benutzer stellen ein Ausgangsvideo zur Verfügung, das als Grundlage für ihre Animation dient. Durch Anpassung verschiedener Parameter wird eine endgültige Animation erstellt, die zusätzlich durch eine Texteingabe gesteuert wird.1 Punkt1 PunktIch versuche mich an Stable, weil kostenneutral. Komme aus dem Fuji-Lager und dann das: offensichtlich war der Sensor zu heiß.
1 PunktStability AI, das Unternehmen u.a. hinter Stable Diffusion hat mit dem Stable Animation SDK ein KI-Tool vorgestellt, mit dem sich Animationen erstellen lassen. Es stehen drei verschiedene Wege zur Verfügung: Via Text-Prompt: Aus einer Texteingabe mit verschiedenen Parametern erstellt Stable Animation eine Animation. Bild und Text-Prompt: Aus einem Ausgangsbild und einer Texteingabe wird die Animation generiert Video und Text-Prompt: Aus einem Video, das z.B. Bewegungsabläufe vorgibt und einer Texteingabe entsteht das Video. Um das SDK zu nutzen, muss auf dem eigenen Rechner das SDK installiert werden, eine ausführliche Dokumentation findet sich in der Dokumentation. Das parallel veröffentlichte Video zeigt anhand von Beispielen, welche Ergebnisse man erzielen kann: Die Kosten für die Nutzung der API werden auf einer eigenen Seite dokumentiert, sie hängen von Auflösung, Länge und Bildfrequenz der Animation ab. Die Pressemitteiung auf deutsch: Stability AI veröffentlicht Stable Animation SDK, ein leistungsstarkes Text-zu-Animationstool für Entwickler 11. Mai – Stability AI, das weltweit führende Open-Source-Unternehmen für künstliche Intelligenz, veröffentlicht heute das Stable Animation SDK, ein Tool für Künstler und Entwickler, mit dem sie die fortschrittlichsten Stable Diffusion-Modelle implementieren können, um beeindruckende Animationen zu erstellen. Benutzer können Animationen auf verschiedene Arten erstellen: durch Eingabeaufforderungen (ohne Bilder), ein Quellbild oder ein Quellvideo. Mit dem Stability AI-Animationsendpunkt können Künstler alle Stable Diffusion-Modelle, einschließlich Stable Diffusion 2.0 und Stable Diffusion XL, zur Erstellung von Animationen verwenden. Wir bieten drei Möglichkeiten zur Erstellung von Animationen: Text zu Animation: Die Benutzer geben eine Texteingabe ein (wie bei Stable Diffusion) und ändern verschiedene Parameter, um eine Animation zu erstellen. Texteingabe + Eingabe eines Ausgangsbildes: Die Benutzer geben ein Ausgangsbild ein, das als Startpunkt ihrer Animation dient. Eine Texteingabe wird in Verbindung mit dem Bild verwendet, um die endgültige Animation zu erzeugen. Videoeingabe + Texteingabe: Die Benutzer stellen ein Ausgangsvideo zur Verfügung, das als Grundlage für ihre Animation dient. Durch Anpassung verschiedener Parameter wird eine endgültige Animation erstellt, die zusätzlich durch eine Texteingabe gesteuert wird.1 Punkt1 PunktIch versuche mich an Stable, weil kostenneutral. Komme aus dem Fuji-Lager und dann das: offensichtlich war der Sensor zu heiß. 1 Punkt1 PunktVielen Dank, es sind tatsächlich fast die ersten Versuche. Ich nutze es lokal: Stable-diffusion-webUI. im Browser ist es nicht so prickelnd. Vorher mit DALL-E imBrowser experimentiert..Ich habe mir einen Prompt gesucht, wo ein Stuhl als Produkt präsentiert wurde, und den dann entspr. modifiziert. Der große Vorteil von SD ist in meinen Auge, dass es lokal laufen kann. mit der LEONARDO.AI, deren Ergebnisse ich fantastisch finde, scheint das nicht zu klappen, obwohl ja auch SD-basiert.1 PunktDanke für den Link. Fotorealistische Ergebnisse bekomme ich schon nach ein paar Tagen Einarbeitung aus Leonardo.AI heraus, Midjourney wird da sicherlich eher besser sein. Ein geübter Fotograf wird in diesen Bildern Schwachstellen und Ungereimtheiten finden, aber der 08/15-Bildkonsument auf der Straße wohl eher nicht. Und an diesen orientieren sich die Kunden letztlich. Der Akt des Fotografierens und der Spaß daran ist natürlich für mich als Amateur gravierend, ebenso wie die Interaktion mit meinem Modell, der Location etc. Aber den "Bildkonsumenten" interessiert das natürlich nicht, einen kommerziellen Kunden schon mal gar nicht. Im Bereich Stock, Food und Architekturfotografie wird es wohl schwer werden, Geld zu verdienen, wie im Video schon zu sehen. Und wir sind ja erst am Anfang dieser Entwicklung...1 Punkt
1 Punkt1 PunktVielen Dank, es sind tatsächlich fast die ersten Versuche. Ich nutze es lokal: Stable-diffusion-webUI. im Browser ist es nicht so prickelnd. Vorher mit DALL-E imBrowser experimentiert..Ich habe mir einen Prompt gesucht, wo ein Stuhl als Produkt präsentiert wurde, und den dann entspr. modifiziert. Der große Vorteil von SD ist in meinen Auge, dass es lokal laufen kann. mit der LEONARDO.AI, deren Ergebnisse ich fantastisch finde, scheint das nicht zu klappen, obwohl ja auch SD-basiert.1 PunktDanke für den Link. Fotorealistische Ergebnisse bekomme ich schon nach ein paar Tagen Einarbeitung aus Leonardo.AI heraus, Midjourney wird da sicherlich eher besser sein. Ein geübter Fotograf wird in diesen Bildern Schwachstellen und Ungereimtheiten finden, aber der 08/15-Bildkonsument auf der Straße wohl eher nicht. Und an diesen orientieren sich die Kunden letztlich. Der Akt des Fotografierens und der Spaß daran ist natürlich für mich als Amateur gravierend, ebenso wie die Interaktion mit meinem Modell, der Location etc. Aber den "Bildkonsumenten" interessiert das natürlich nicht, einen kommerziellen Kunden schon mal gar nicht. Im Bereich Stock, Food und Architekturfotografie wird es wohl schwer werden, Geld zu verdienen, wie im Video schon zu sehen. Und wir sind ja erst am Anfang dieser Entwicklung...1 Punkt

































































.jpg.e8e7d80af04843577f1fe78ad4f05aab.jpg)




















































































Account
Suche
Configure browser push notifications
Chrome (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions → Notifications.
- Adjust your preference.
Chrome (Desktop)
- Click the padlock icon in the address bar.
- Select Site settings.
- Find Notifications and adjust your preference.
Safari (iOS 16.4+)
- Ensure the site is installed via Add to Home Screen.
- Open Settings App → Notifications.
- Find your app name and adjust your preference.
Safari (macOS)
- Go to Safari → Preferences.
- Click the Websites tab.
- Select Notifications in the sidebar.
- Find this website and adjust your preference.
Edge (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions.
- Find Notifications and adjust your preference.
Edge (Desktop)
- Click the padlock icon in the address bar.
- Click Permissions for this site.
- Find Notifications and adjust your preference.
Firefox (Android)
- Go to Settings → Site permissions.
- Tap Notifications.
- Find this site in the list and adjust your preference.
Firefox (Desktop)
- Open Firefox Settings.
- Search for Notifications.
- Find this site in the list and adjust your preference.