

_055d65.png)
_ee1da0.png)
Rangliste
-
adrianrohnfelder
Moderators76Punkte286Gesamte Inhalte -
Mattes
Mitglieder60Punkte89Gesamte Inhalte -

Zauberfrau
Mitglieder24Punkte53Gesamte Inhalte -
Andreas J.
Administrators21Punkte198Gesamte Inhalte




Beliebte Inhalte
Inhalte mit der höchsten Reputation seit 12.04.2023 in Beiträge anzeigen
-
4 Punkte4 PunkteIch habe mal wieder mit etwas ganz einfachem experimentiert und zwar mit dem Prompt MOTIV in the bottle, black background. Hat was 🙂






 3 PunkteSpannend finde ich auch, was herauskommt, wenn man Firefly einfach mal "machen lässt", also keine Vorgabe in den Prompt schreibt. Original: Drei "Vorschläge" aus Firefly:
3 PunkteSpannend finde ich auch, was herauskommt, wenn man Firefly einfach mal "machen lässt", also keine Vorgabe in den Prompt schreibt. Original: Drei "Vorschläge" aus Firefly:


 3 PunkteTop! Sieht sehr gut aus. Autos gehen auch mit SD. Aber bei den Umgebungsvariablen braucht es oft etliche Versuche. Ich suche mir meist einen passenden Promt bei civitai und verändere dann die mir wichtigen Variablen, wie (hier) Autotyp, Tageszeit, Gebäude, Umgebung allgemein... Die letzten beiden sollten Plymouth Fury werden, zu Mittag in einer Staubwüste...
3 PunkteTop! Sieht sehr gut aus. Autos gehen auch mit SD. Aber bei den Umgebungsvariablen braucht es oft etliche Versuche. Ich suche mir meist einen passenden Promt bei civitai und verändere dann die mir wichtigen Variablen, wie (hier) Autotyp, Tageszeit, Gebäude, Umgebung allgemein... Die letzten beiden sollten Plymouth Fury werden, zu Mittag in einer Staubwüste...

 3 PunkteNatürlich musste ich die Integration von Adobe Firefly in Adobe Photoshop gleich einmal ausprobieren 🙂 Aktuell funktioniert das nur in der Desktop Beta-Version von Photoshop. Die findet Ihr in der Creative Cloud unter den Beta-Applikationen und könnt sie von dort aus parallel zu der 'normalen' Photoshop Version zusätzlich installieren. In der Photoshop Beta öffnet Ihr Euer Bild und markiert mit einem Auswahlwerkzeug den Bereich, dem Ihr etwas hinzufügen möchtet. Es erscheint automatisch ein Kontextmenü in welches Ihr (auf Englisch) eingeben könnt, was dem Bereich hinzugefügt werden soll wie z.B. "add a dinosaur". Anschließend drückt Ihr auf 'Generieren', wartet kurz (oder länger je nach Rechner) und erhaltet dann drei alternative Motive vorgeschlagen. Ihr müsst dabei mit dem Internet verbunden sein, da die Funktion 'Generative Füllung' eine Cloud-Verarbeitung erfordert. Das geht super einfach und macht richtig Spaß. Allerdings sind die Ergebnisse sehr durchwachsen. Manchmal funktioniert es super, manche Motive sind einfach nur gruselig (da ist Midjourney in der Qualität noch um Welten besser als Adobe Firefly). Manchmal passen die Schatten und das Licht, manchmal gar nicht. Auch die Größenverhältnisse und Perspektiven machen nicht immer Sinn. Grundsätzlich zeigt die Beta-Version jedoch das enorme Potential und könnte in der Tat ein echter Gamechanger werden.
3 PunkteNatürlich musste ich die Integration von Adobe Firefly in Adobe Photoshop gleich einmal ausprobieren 🙂 Aktuell funktioniert das nur in der Desktop Beta-Version von Photoshop. Die findet Ihr in der Creative Cloud unter den Beta-Applikationen und könnt sie von dort aus parallel zu der 'normalen' Photoshop Version zusätzlich installieren. In der Photoshop Beta öffnet Ihr Euer Bild und markiert mit einem Auswahlwerkzeug den Bereich, dem Ihr etwas hinzufügen möchtet. Es erscheint automatisch ein Kontextmenü in welches Ihr (auf Englisch) eingeben könnt, was dem Bereich hinzugefügt werden soll wie z.B. "add a dinosaur". Anschließend drückt Ihr auf 'Generieren', wartet kurz (oder länger je nach Rechner) und erhaltet dann drei alternative Motive vorgeschlagen. Ihr müsst dabei mit dem Internet verbunden sein, da die Funktion 'Generative Füllung' eine Cloud-Verarbeitung erfordert. Das geht super einfach und macht richtig Spaß. Allerdings sind die Ergebnisse sehr durchwachsen. Manchmal funktioniert es super, manche Motive sind einfach nur gruselig (da ist Midjourney in der Qualität noch um Welten besser als Adobe Firefly). Manchmal passen die Schatten und das Licht, manchmal gar nicht. Auch die Größenverhältnisse und Perspektiven machen nicht immer Sinn. Grundsätzlich zeigt die Beta-Version jedoch das enorme Potential und könnte in der Tat ein echter Gamechanger werden.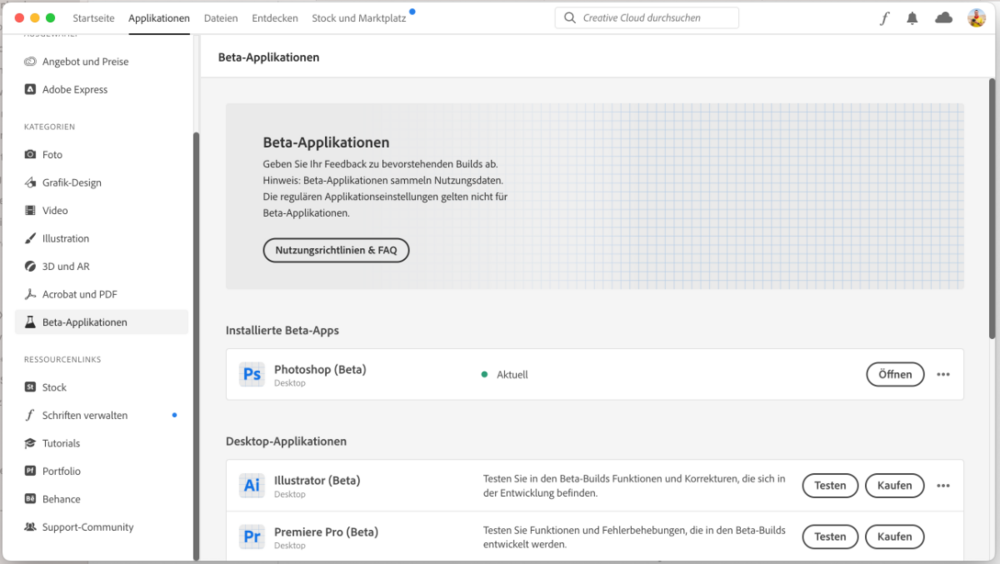



 2 Punkte2 PunkteHallo. Gestern hat Leonardo.AI im Rahmen eines größeres Updates SDXL 0.9 und Prompt Magic 3.0 ergänzt. Nach meiner Einschätzung ist das nochmals ein deutlicher Sprung nach vorn. Hier mal ein paar Beispiele:
2 Punkte2 PunkteHallo. Gestern hat Leonardo.AI im Rahmen eines größeres Updates SDXL 0.9 und Prompt Magic 3.0 ergänzt. Nach meiner Einschätzung ist das nochmals ein deutlicher Sprung nach vorn. Hier mal ein paar Beispiele:
 2 Punkte2 PunkteIch bin immer noch beeindruckt. Und immer noch ein wenig erschrocken…
2 Punkte2 PunkteIch bin immer noch beeindruckt. Und immer noch ein wenig erschrocken…

 2 Punkte2 PunkteWenn du mit der Gallerie die MJ-App meinst, wo man alle seine Bilder ohne Discord sieht: Stimmt, die ist großer Mist. Noch! Sie soll wohl recht mächtig werden, sodass man sogar dort ohne Discord seine Bilder generieren kann. Allerdings ist das Ding wohl noch lange nicht so weit und die zu Verfügung stehenden Funktionen wie das Verwalten der Bilder sind mau. Aber es gibt die Möglichkeit, die alte Gallerie wieder aus der Gruft zu holen: https://legacy.midjourney.com/app/ Da isse. ☺️ Hat mich auch geärgert. Auf dem MJ-Discord-Server kann im Kanal # web-feedback munter darüber diskutiert werden. Hier wirst du jede Menge Gleichgesinnte finden. 😉2 Punkte2 PunkteHallo Zusammen, ich bin Hobbyfotograf und bisher ein absoluter Rookie in Sachen AI Art. Gestern habe ich Leonardo AI für mich entdeckt und seitdem viel ausprobiert. Gerade habe ich dieses Forum entdeckt und mich sofort angemeldet. 🙂 Hier mal einige Beispiele meiner bisherigen Bilder. Allesamt Photo real. Bin mit den Ergebnissen bis auf ein paar Details sehr zufrieden für den Anfang. Was sagt ihr?
2 Punkte2 PunkteWenn du mit der Gallerie die MJ-App meinst, wo man alle seine Bilder ohne Discord sieht: Stimmt, die ist großer Mist. Noch! Sie soll wohl recht mächtig werden, sodass man sogar dort ohne Discord seine Bilder generieren kann. Allerdings ist das Ding wohl noch lange nicht so weit und die zu Verfügung stehenden Funktionen wie das Verwalten der Bilder sind mau. Aber es gibt die Möglichkeit, die alte Gallerie wieder aus der Gruft zu holen: https://legacy.midjourney.com/app/ Da isse. ☺️ Hat mich auch geärgert. Auf dem MJ-Discord-Server kann im Kanal # web-feedback munter darüber diskutiert werden. Hier wirst du jede Menge Gleichgesinnte finden. 😉2 Punkte2 PunkteHallo Zusammen, ich bin Hobbyfotograf und bisher ein absoluter Rookie in Sachen AI Art. Gestern habe ich Leonardo AI für mich entdeckt und seitdem viel ausprobiert. Gerade habe ich dieses Forum entdeckt und mich sofort angemeldet. 🙂 Hier mal einige Beispiele meiner bisherigen Bilder. Allesamt Photo real. Bin mit den Ergebnissen bis auf ein paar Details sehr zufrieden für den Anfang. Was sagt ihr?


 2 Punkte2 PunkteLicht und Farbe lagen an meinem Prompt, ich wollte auf eine "Cyberpunk"-Atmosphäre hinaus. Es geht aber auch ganz anders:
2 Punkte2 PunkteLicht und Farbe lagen an meinem Prompt, ich wollte auf eine "Cyberpunk"-Atmosphäre hinaus. Es geht aber auch ganz anders: 2 Punkte2 Punkte2 Punkte2 PunkteHallo, ich habe mich heute erst hier registriert und hier sind einige Sachen aus meinen ersten Tagen bei Leo A.I. von vor Monaten bis heute. Nicht alles ist gut, vieles nicht geupscaled, aber so in etwa sieht meine Scifi Welt aus. Dies ist nur ein kleiner Ausschnitt. Vieles ist brauchbar und dient eher als Motivation/Inspiration.
2 Punkte2 Punkte2 Punkte2 PunkteHallo, ich habe mich heute erst hier registriert und hier sind einige Sachen aus meinen ersten Tagen bei Leo A.I. von vor Monaten bis heute. Nicht alles ist gut, vieles nicht geupscaled, aber so in etwa sieht meine Scifi Welt aus. Dies ist nur ein kleiner Ausschnitt. Vieles ist brauchbar und dient eher als Motivation/Inspiration.





.thumb.jpg.3693ddc8c13a552c1f34b01d0ed214ab.jpg)

















 2 PunkteIst vielleicht Eulen nach Athen getragen. Aber ich habe zwei ganz interessante Tutorials in deutscher Sprache auf Youtube gefunden. Midjourney-Tutorial auf Deutsch für Anfänger (Youtube) Dieses Tutorial startet tatsächlich bei Null (Anmeldung bei Discord, Midjourney usw.). Allerdings finde ich am Ende viele Infos sehr cool, die ich selbst noch nicht wusste. Zum Beispiel wurde auf zwei interessante Webseiten verwiesen, womit man das Prompting besser gestalten kann. Ohne die beiden Links jetzt selbst schon getestet zu haben sind das: Midlibrary.IO (Webeseiten-Link) Das scheint eine Art Bibliothek zu sein, wo man sich schlau machen kann, welcher Prompt welchen Stil hervorbringt. Mit über 3000 Beispielbildern. (noch ungetestet) Prompt.Noonshot.com (Webseiten-Link) Ist zwar für Version 4, fest eingestellt, man kann aber seinen Prompt damit erstellen und nach dem Kopieren auf Discord gerade das "--v 4" dahinter löschen, wenn man das nicht will. Ansonsten scheint es ganz gut zu sein, sich einen Prompt mit entsprechendem Licht usw. zusammenzuklickern. (wie gesagt, noch ungetestet) Dann habe ich mir noch für alle Anime- und Manga-Fans dieses Youtube-Tutorial gegönnt: Anime AI Art Guide (Youtube) Ist eine schnelle Zusammenfassung, was mit dem --niji - Parameter bei Midjourney alles möglich ist. Bin zwar jetzt nicht so im Niji-Umfeld zuhause, fand das aber recht interessant. Vielleicht ist für den ein oder anderen was Brauchbares dabei. Ich wollte es hier nicht unerwähnt lassen. 😊 Viele Grüße von der Zauberfrau2 Punkte2 PunkteDie Kombination aus "Prompt Magic v3.0" und "Photoreal" kann was:
2 PunkteIst vielleicht Eulen nach Athen getragen. Aber ich habe zwei ganz interessante Tutorials in deutscher Sprache auf Youtube gefunden. Midjourney-Tutorial auf Deutsch für Anfänger (Youtube) Dieses Tutorial startet tatsächlich bei Null (Anmeldung bei Discord, Midjourney usw.). Allerdings finde ich am Ende viele Infos sehr cool, die ich selbst noch nicht wusste. Zum Beispiel wurde auf zwei interessante Webseiten verwiesen, womit man das Prompting besser gestalten kann. Ohne die beiden Links jetzt selbst schon getestet zu haben sind das: Midlibrary.IO (Webeseiten-Link) Das scheint eine Art Bibliothek zu sein, wo man sich schlau machen kann, welcher Prompt welchen Stil hervorbringt. Mit über 3000 Beispielbildern. (noch ungetestet) Prompt.Noonshot.com (Webseiten-Link) Ist zwar für Version 4, fest eingestellt, man kann aber seinen Prompt damit erstellen und nach dem Kopieren auf Discord gerade das "--v 4" dahinter löschen, wenn man das nicht will. Ansonsten scheint es ganz gut zu sein, sich einen Prompt mit entsprechendem Licht usw. zusammenzuklickern. (wie gesagt, noch ungetestet) Dann habe ich mir noch für alle Anime- und Manga-Fans dieses Youtube-Tutorial gegönnt: Anime AI Art Guide (Youtube) Ist eine schnelle Zusammenfassung, was mit dem --niji - Parameter bei Midjourney alles möglich ist. Bin zwar jetzt nicht so im Niji-Umfeld zuhause, fand das aber recht interessant. Vielleicht ist für den ein oder anderen was Brauchbares dabei. Ich wollte es hier nicht unerwähnt lassen. 😊 Viele Grüße von der Zauberfrau2 Punkte2 PunkteDie Kombination aus "Prompt Magic v3.0" und "Photoreal" kann was: 2 PunkteSuperdog 😅2 Punkte2 PunkteHallo, ich bin der Spanksen (Murat) - freut mich ein Teil der AI Community sein zu dürfen. Im Moment reizt es mich gerade mit Generative Fill alten Bildern von mir neues Leben einzuhauchen und eine Story zu erzählen die vorher nicht da war oder die ich im Kopf hatte aber nicht umsetzten konnte. Die alten Bilder inspirieren mich grade dadurch komplett neu. Hier mal ein paar Beispiele Hier zum Beispiel das große Problem des Drogen- und Tablettenmissbrauchs (Oxys, Benzos etc.) was wir auf Sylt mit sehr vielen Jugendlichen auf Sylt (und nicht nur hier natürlich) haben sowie die Perspektivlosigkeit im starken Kontrast zur Schönheit der Insel.2 PunkteDie Stimmung in einem verschneiten Wald ist gut getroffen, finde ich:
2 PunkteSuperdog 😅2 Punkte2 PunkteHallo, ich bin der Spanksen (Murat) - freut mich ein Teil der AI Community sein zu dürfen. Im Moment reizt es mich gerade mit Generative Fill alten Bildern von mir neues Leben einzuhauchen und eine Story zu erzählen die vorher nicht da war oder die ich im Kopf hatte aber nicht umsetzten konnte. Die alten Bilder inspirieren mich grade dadurch komplett neu. Hier mal ein paar Beispiele Hier zum Beispiel das große Problem des Drogen- und Tablettenmissbrauchs (Oxys, Benzos etc.) was wir auf Sylt mit sehr vielen Jugendlichen auf Sylt (und nicht nur hier natürlich) haben sowie die Perspektivlosigkeit im starken Kontrast zur Schönheit der Insel.2 PunkteDie Stimmung in einem verschneiten Wald ist gut getroffen, finde ich:



 2 Punkte2 PunkteSehr sehr cool, also Bilder und Geschichte. Du kennst doch sicher die Bücher "His Dark Materials" wo die Personen einen Dämonen in Form eines Tieres haben. Daran musste ich sofort bei dem Waschbär denken.2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 PunkteKleine Spielerei zwischendurch mit dem Prompt [FILMTITEL] isometric cube micro world underground cut away Wer kann die Filme zuordnen: Alien, Westworld, Mad Max, Ready Player One, Pirates of the Carribean, Blade Runner, Interstellar, Harry Potter, Star Wars Mustafar, Star Wars Tatooine, Indiana Jones, Mordor Herr der Ringe? Jetzt dürft Ihr 😉
2 Punkte2 PunkteSehr sehr cool, also Bilder und Geschichte. Du kennst doch sicher die Bücher "His Dark Materials" wo die Personen einen Dämonen in Form eines Tieres haben. Daran musste ich sofort bei dem Waschbär denken.2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 Punkte2 PunkteKleine Spielerei zwischendurch mit dem Prompt [FILMTITEL] isometric cube micro world underground cut away Wer kann die Filme zuordnen: Alien, Westworld, Mad Max, Ready Player One, Pirates of the Carribean, Blade Runner, Interstellar, Harry Potter, Star Wars Mustafar, Star Wars Tatooine, Indiana Jones, Mordor Herr der Ringe? Jetzt dürft Ihr 😉










 2 PunkteJa, genau hier ist der Ansatz. Wir müssen damit umgehen lernen, wie mit dem Telefon (war vor gut 100 Jahren angeblich eine riesige Diskussion, ob das Telefon nicht entmenschlicht), dem Handy oder dem Internet.2 PunkteDarum habe ich ja auch "lasse ich mich von Chat GPT unterstützen" geschrieben. Es ist super, um mal eine Idee zu bekommen oder etwas auszuschmücken, mit Sparringspartner beschreibst Du das sehr gut. Ähnlich würde ich auch die Bilder von Storybird sehen, als eine Idee oder Alternative, die man selbst so nicht im Kopf hatte. Wie geschrieben, ich schaue mir das zumindest einmal an.2 Punkte2 PunkteYep, das ist echt unglaublich wie gut insbesondere das Erweitern von Fotos funktioniert, der rote Rahmen zeigt das originale Bild.
2 PunkteJa, genau hier ist der Ansatz. Wir müssen damit umgehen lernen, wie mit dem Telefon (war vor gut 100 Jahren angeblich eine riesige Diskussion, ob das Telefon nicht entmenschlicht), dem Handy oder dem Internet.2 PunkteDarum habe ich ja auch "lasse ich mich von Chat GPT unterstützen" geschrieben. Es ist super, um mal eine Idee zu bekommen oder etwas auszuschmücken, mit Sparringspartner beschreibst Du das sehr gut. Ähnlich würde ich auch die Bilder von Storybird sehen, als eine Idee oder Alternative, die man selbst so nicht im Kopf hatte. Wie geschrieben, ich schaue mir das zumindest einmal an.2 Punkte2 PunkteYep, das ist echt unglaublich wie gut insbesondere das Erweitern von Fotos funktioniert, der rote Rahmen zeigt das originale Bild.
 2 PunkteAber die Herr der Ringe Bücher hat es gelesen 🙂
2 PunkteAber die Herr der Ringe Bücher hat es gelesen 🙂 2 Punkte2 PunkteEine Möglichkeit wäre es zudem, dass Du Dir jeweils ein Graffiti für jeden einzelnen Buchstaben generieren lässt, das sollte funktionieren. Und dann alle Buchstaben in z.B. Photoshop zu einem Graffiti zusammenbaust. Dazu nutzt Du am besten bei jedem Bild den gleichen --seed. Aber klar, ist deutlich aufwendiger.2 Punkte2 PunkteHier mal noch zwei Ergebnisse von heute. Bis auf die Augen schon sehr ansehnlich finde ich. Und Supergirl darf nicht fehlen 😄
2 Punkte2 PunkteEine Möglichkeit wäre es zudem, dass Du Dir jeweils ein Graffiti für jeden einzelnen Buchstaben generieren lässt, das sollte funktionieren. Und dann alle Buchstaben in z.B. Photoshop zu einem Graffiti zusammenbaust. Dazu nutzt Du am besten bei jedem Bild den gleichen --seed. Aber klar, ist deutlich aufwendiger.2 Punkte2 PunkteHier mal noch zwei Ergebnisse von heute. Bis auf die Augen schon sehr ansehnlich finde ich. Und Supergirl darf nicht fehlen 😄
 2 Punkte2 PunkteHallo. Meine ersten Gehversuche habe ich mit Leonardo.AI gemacht. Hier möchte ich Euch einige meiner Portraits zeigen und lade jeden herzlich ein, sich mit seinen Bildern zu beteiligen... Viele Grüße Mattes
2 Punkte2 PunkteHallo. Meine ersten Gehversuche habe ich mit Leonardo.AI gemacht. Hier möchte ich Euch einige meiner Portraits zeigen und lade jeden herzlich ein, sich mit seinen Bildern zu beteiligen... Viele Grüße Mattes

 2 PunkteHallo. Midjourney bekommt nach meinen Tests Fahrzeuge besser hin, aber Leonardo ist auch nicht so schlecht: Grüße Matthias
2 PunkteHallo. Midjourney bekommt nach meinen Tests Fahrzeuge besser hin, aber Leonardo ist auch nicht so schlecht: Grüße Matthias

 2 Punkte2 PunkteMidjourney habe ich schon getestet bevor es dann kostenpflichtig wurde. Aktuell habe ich außer "rumspielen" noch keine Verwendung für die Bilder und daher auch keinen kostenpflichtigen Account. Prompt von der Dame mit Katze war: Und die sitzende Dame: Zusammenfassend kann man sagen bei 10 Bildern kommt 2-3 mal was richtig übles raus, 1 mal was richtig gutes und der Rest ist brauchbar. Meine besten Bilder kann ich hier nicht zeigen, da ich auch ein wenig mit NSFW Content herumgespielt habe wenn das ganze schon unzensiert ist 😄 Was ich interessant finde ist, dass die freien Varianten so schnell aufholen. Und das kann fast jeder mit nem halbwegs guten Rechner erstellen (Bei meinem betagten Ryzen 7 2700X mit Geforce 1080ti dauert ein Bild hochskaliert auf 1024*1024 ca 30-40s). Auf meinem M1 Macbook gehts etwas langsamer aber auch problemlos. Das Modell ist grade mal 2GB groß und das Programm an sich 6GB. Also Peanuts. Da steckt echt ne pfiffige Community dahinter. Wenn das so weitergeht können sich die etablierten kostenpflichtigen bald warm anziehen.2 Punkte2 PunkteIch habe nun einiges mit Stable Diffusion aus meinem Link oben experimentiert. Wichtig ist das Model das man dazu nutzt. Ich habe viel mit dem "analog Madness" von civitai.com herumprobiert nun. Da kommen teils schon sehr gute Ergebnisse raus, teils auch ziemlicher Mist vor allem wenn man etwas komplexere Dinge haben will wie hier z.B. Die Dame sollte doch nur eine Katze auf der Schulter haben aber stattdessen hat sie noch einen Katzenpelz und Katzenohren bekommen sowie eine verunstaltete Katze im Hintergrund 😄 Wenns dann nur eine Frau sein soll geht das schon besser:
2 Punkte2 PunkteMidjourney habe ich schon getestet bevor es dann kostenpflichtig wurde. Aktuell habe ich außer "rumspielen" noch keine Verwendung für die Bilder und daher auch keinen kostenpflichtigen Account. Prompt von der Dame mit Katze war: Und die sitzende Dame: Zusammenfassend kann man sagen bei 10 Bildern kommt 2-3 mal was richtig übles raus, 1 mal was richtig gutes und der Rest ist brauchbar. Meine besten Bilder kann ich hier nicht zeigen, da ich auch ein wenig mit NSFW Content herumgespielt habe wenn das ganze schon unzensiert ist 😄 Was ich interessant finde ist, dass die freien Varianten so schnell aufholen. Und das kann fast jeder mit nem halbwegs guten Rechner erstellen (Bei meinem betagten Ryzen 7 2700X mit Geforce 1080ti dauert ein Bild hochskaliert auf 1024*1024 ca 30-40s). Auf meinem M1 Macbook gehts etwas langsamer aber auch problemlos. Das Modell ist grade mal 2GB groß und das Programm an sich 6GB. Also Peanuts. Da steckt echt ne pfiffige Community dahinter. Wenn das so weitergeht können sich die etablierten kostenpflichtigen bald warm anziehen.2 Punkte2 PunkteIch habe nun einiges mit Stable Diffusion aus meinem Link oben experimentiert. Wichtig ist das Model das man dazu nutzt. Ich habe viel mit dem "analog Madness" von civitai.com herumprobiert nun. Da kommen teils schon sehr gute Ergebnisse raus, teils auch ziemlicher Mist vor allem wenn man etwas komplexere Dinge haben will wie hier z.B. Die Dame sollte doch nur eine Katze auf der Schulter haben aber stattdessen hat sie noch einen Katzenpelz und Katzenohren bekommen sowie eine verunstaltete Katze im Hintergrund 😄 Wenns dann nur eine Frau sein soll geht das schon besser:
 2 PunkteIch habe im Prompt "faded Kodachrome colors" angegeben, das funktioniert ziemlich gut. Ohne das "faded" (also etwa: "verblasst") sind mir die Farben zu kräftig. Das geht dann auch, sieht aber mehr nach Eggleston aus, als ich es hier haben wollte.2 PunkteHabe ich die Tage auch mal wieder ausprobiert. Die Ergebnisse sind in der Tat nicht verkehrt. Ich bevorzuge immer noch Midjourney, aber die Bing/ Dall-E Ergebnisse sind durchaus brauchbar.
2 PunkteIch habe im Prompt "faded Kodachrome colors" angegeben, das funktioniert ziemlich gut. Ohne das "faded" (also etwa: "verblasst") sind mir die Farben zu kräftig. Das geht dann auch, sieht aber mehr nach Eggleston aus, als ich es hier haben wollte.2 PunkteHabe ich die Tage auch mal wieder ausprobiert. Die Ergebnisse sind in der Tat nicht verkehrt. Ich bevorzuge immer noch Midjourney, aber die Bing/ Dall-E Ergebnisse sind durchaus brauchbar.
 2 PunkteMit SD habe ich leider noch nicht wirklich gearbeitet, ich meine aber @aicatcher bereits? Ansonsten habe ich ohne Ahnung zu haben 🙂 quick&dirty dieses Video gefunden, ist es das was Du suchst? https://www.youtube.com/watch?v=YSqQ67Z0U5U2 Punkte2 PunkteLetzter Test für heute: Drachen. Dieses Motiv ist für mich eine der größten Herausforderungen, die Physiognomie hat bisher so gut wie nie funktioniert. Prompt: dangerous malevolent fire breathing dragon, full body, with glowing eyes and large leathery wings and sharp talons fights against an large army of heavily-armored dwarves in the region of Mordor, flames, debris, scene of desctruction, dramatic light, cinematic lighting v5 v5.1 v5.1 --style raw Also hier hat v5.1 eindeutige Fortschritte gemacht! Auch die Zwergenarmee hat in v5.1 immerhin einmal funktioniert. Wenn jetzt auch noch das Feuer spucken klappen würde 🤪, aber gut, v5.2 und v6 dürfen ja auch noch Raum für Verbesserungen haben 🙂
2 PunkteMit SD habe ich leider noch nicht wirklich gearbeitet, ich meine aber @aicatcher bereits? Ansonsten habe ich ohne Ahnung zu haben 🙂 quick&dirty dieses Video gefunden, ist es das was Du suchst? https://www.youtube.com/watch?v=YSqQ67Z0U5U2 Punkte2 PunkteLetzter Test für heute: Drachen. Dieses Motiv ist für mich eine der größten Herausforderungen, die Physiognomie hat bisher so gut wie nie funktioniert. Prompt: dangerous malevolent fire breathing dragon, full body, with glowing eyes and large leathery wings and sharp talons fights against an large army of heavily-armored dwarves in the region of Mordor, flames, debris, scene of desctruction, dramatic light, cinematic lighting v5 v5.1 v5.1 --style raw Also hier hat v5.1 eindeutige Fortschritte gemacht! Auch die Zwergenarmee hat in v5.1 immerhin einmal funktioniert. Wenn jetzt auch noch das Feuer spucken klappen würde 🤪, aber gut, v5.2 und v6 dürfen ja auch noch Raum für Verbesserungen haben 🙂

 2 PunkteDa gehe ich mit. Die klassischen Tiles bei Etsy und co sind seit midjourney tile release ziemlich stark gesunken. Ich versuche gerade etwas modulares für die Dungeons & Dragons Gemeinde aufzubauen, mal schauen ob das funktioniert. So ein Unterforum wäre stark.2 Punkte2 PunkteEinfach unfassbar wie schnell wir uns mittlerweile in Richtung lebensechte Fotos bewegen. Klar sieht man es hier und da noch an Details (Augen, Gesichtsformen usw) aber wenn man bedenkt, dass wir erst in einem Jahr Entwicklung sind, ist es fast schon unfassbar. Hier mal meine Bilder:
2 PunkteDa gehe ich mit. Die klassischen Tiles bei Etsy und co sind seit midjourney tile release ziemlich stark gesunken. Ich versuche gerade etwas modulares für die Dungeons & Dragons Gemeinde aufzubauen, mal schauen ob das funktioniert. So ein Unterforum wäre stark.2 Punkte2 PunkteEinfach unfassbar wie schnell wir uns mittlerweile in Richtung lebensechte Fotos bewegen. Klar sieht man es hier und da noch an Details (Augen, Gesichtsformen usw) aber wenn man bedenkt, dass wir erst in einem Jahr Entwicklung sind, ist es fast schon unfassbar. Hier mal meine Bilder:
 2 Punkte1 PunktSo. Ich habe mal ein bisschen mit der Pan-Funktion gespielt. Ich dachte, ich könnte damit vielleicht ein nettes Fantasy-Band erzeugen, das ich irgendwo als Schmuck auf meine Webseite packen kann. Nun, davon werde ich absehen. Trotzdem sind die Ergebnisse ganz nett. Ich habe die Bilder immer nach rechts mit der Pan-Funktion erweitert. Wenn man sie nicht zwischendrin mit Zoom behandelt (was ja die Auflösung wieder verkleinert), werden die Bilder riesig! Wenn die Bilder so untereinander sind, sieht man schön, wo ich mich beim Entwickeln verzweigt habe. Leider hat sich der Stil doch sehr drastisch verändert. Und das untere Bild hat was von Barbies Welt... Es war ein interessanter Versuch, der Spaß gemacht hat. Die Prompts habe ich tatsächlich variiert. Bis zum Drachen waren sie auch ziemlich gleich. Beim weißen Drachen entstand aber eine Wasserlandschaft, während der rosa (🙄) Drache in den Bergen blieb. Da habe ich dann den Prompt geändert. Oben habe ich "wide ocean" zu meinem Prompt ("Suggestions for a beautiful background für a fantasy website, In the distance you can see in pastel colors ...") hinzugefügt, im unteren Bild "a mountain range with a populated ancient Inca city" - Letzteres allerdings ohne Erfolg. Zwar finde ich den rosa Drachen anatomisch ziemlich gut (zumindest hat er zwei Flügel). Der andere sitzt aber definitv farblich und motivtechnisch in ansprechenderen Bild.
2 Punkte1 PunktSo. Ich habe mal ein bisschen mit der Pan-Funktion gespielt. Ich dachte, ich könnte damit vielleicht ein nettes Fantasy-Band erzeugen, das ich irgendwo als Schmuck auf meine Webseite packen kann. Nun, davon werde ich absehen. Trotzdem sind die Ergebnisse ganz nett. Ich habe die Bilder immer nach rechts mit der Pan-Funktion erweitert. Wenn man sie nicht zwischendrin mit Zoom behandelt (was ja die Auflösung wieder verkleinert), werden die Bilder riesig! Wenn die Bilder so untereinander sind, sieht man schön, wo ich mich beim Entwickeln verzweigt habe. Leider hat sich der Stil doch sehr drastisch verändert. Und das untere Bild hat was von Barbies Welt... Es war ein interessanter Versuch, der Spaß gemacht hat. Die Prompts habe ich tatsächlich variiert. Bis zum Drachen waren sie auch ziemlich gleich. Beim weißen Drachen entstand aber eine Wasserlandschaft, während der rosa (🙄) Drache in den Bergen blieb. Da habe ich dann den Prompt geändert. Oben habe ich "wide ocean" zu meinem Prompt ("Suggestions for a beautiful background für a fantasy website, In the distance you can see in pastel colors ...") hinzugefügt, im unteren Bild "a mountain range with a populated ancient Inca city" - Letzteres allerdings ohne Erfolg. Zwar finde ich den rosa Drachen anatomisch ziemlich gut (zumindest hat er zwei Flügel). Der andere sitzt aber definitv farblich und motivtechnisch in ansprechenderen Bild.
 1 Punkt1 PunktIch habe vor langer Zeit die ersten drei Bücher gelesen und war begeistert von den Welten und Figuren die Pullman da skizziert hat, wobei ich mich ehrlich gesagt gar nicht mehr an die Auflösung erinnern kann (gut, spricht nicht ganz für die Story). Im Moment schaue ich mir die Serie dazu an, ist auf jeden Fall nett anzusehen mit tollen Schauspielern. Ich habe allerdings das Gefühl, dass in der Serie die Botschaft "böse Kirche" doch etwas mehr strapaziert wird als in den Büchern, das stört in der Tat. Mir hat aber die Idee mit den Dämonen richtig gut gefallen und insbesondere auch das Wandern zwischen den Welten. Die Vorstellung von Parallelwelten finde ich generell einfach super und beschäftige mich dazu auch mit den unterschiedlichen Theorien in der Astrophysik. Dann bin ich aber erst einmal gespannt wie die Story rund um Chamäleon weitergeht 🙂1 PunktBoah, schwer! Teilweise. Ich kenne auch einige Filme nicht oder nicht so genau, dass ich es zuordnen könnte. Madmax ist z.B. schon gefühlte Jahrhunderte her, dass ich es gesehen habe. Ich versuche mich mal (Buchstaben definieren Zeilen, Zahlen definieren Reihen): A1: A2: Harry Potter A3: A4: B1: Interstellar B2: Indiana Jones? B3: HdR - Mordor B4: Fluch der Karibik C1: C2: Star Wars Tatooine C3: C4: Tja, mehr krieg ich nicht hin. Hab mich auch mal versucht: Allerdings habe ich festgestellt, dass bei Filmtiteln, die eigentlich mehr genrell gehalten werden, besser noch ein Movie davorkommt (oder eben auch der Produzent). Hier sind meine gewählten Filme (es sind auch ein paar richtig alte dabei)/Themen: Back to the Future, Captain Future, Corpse Bride, Despicable Me, James Cameron's Avatar, Logans Run (2x), Madagascar (Dreamworks), Moby Dick, Monsters Inc., Nightmare before Christmas, Saint-Exupéry's The Little Prince, Star Trek - The next Generation, The Halleluja Trail (40 Wagen westwärts), The Thief of Bagdad Manche könnte man sich tatsächlich als Diorama ins Zimmer stellen. Manche erkennt man aber auch gleich gar nicht. Logans Run gibt es zweimal. Einmal ohne Movie vornedran und einmal mit.
1 Punkt1 PunktIch habe vor langer Zeit die ersten drei Bücher gelesen und war begeistert von den Welten und Figuren die Pullman da skizziert hat, wobei ich mich ehrlich gesagt gar nicht mehr an die Auflösung erinnern kann (gut, spricht nicht ganz für die Story). Im Moment schaue ich mir die Serie dazu an, ist auf jeden Fall nett anzusehen mit tollen Schauspielern. Ich habe allerdings das Gefühl, dass in der Serie die Botschaft "böse Kirche" doch etwas mehr strapaziert wird als in den Büchern, das stört in der Tat. Mir hat aber die Idee mit den Dämonen richtig gut gefallen und insbesondere auch das Wandern zwischen den Welten. Die Vorstellung von Parallelwelten finde ich generell einfach super und beschäftige mich dazu auch mit den unterschiedlichen Theorien in der Astrophysik. Dann bin ich aber erst einmal gespannt wie die Story rund um Chamäleon weitergeht 🙂1 PunktBoah, schwer! Teilweise. Ich kenne auch einige Filme nicht oder nicht so genau, dass ich es zuordnen könnte. Madmax ist z.B. schon gefühlte Jahrhunderte her, dass ich es gesehen habe. Ich versuche mich mal (Buchstaben definieren Zeilen, Zahlen definieren Reihen): A1: A2: Harry Potter A3: A4: B1: Interstellar B2: Indiana Jones? B3: HdR - Mordor B4: Fluch der Karibik C1: C2: Star Wars Tatooine C3: C4: Tja, mehr krieg ich nicht hin. Hab mich auch mal versucht: Allerdings habe ich festgestellt, dass bei Filmtiteln, die eigentlich mehr genrell gehalten werden, besser noch ein Movie davorkommt (oder eben auch der Produzent). Hier sind meine gewählten Filme (es sind auch ein paar richtig alte dabei)/Themen: Back to the Future, Captain Future, Corpse Bride, Despicable Me, James Cameron's Avatar, Logans Run (2x), Madagascar (Dreamworks), Moby Dick, Monsters Inc., Nightmare before Christmas, Saint-Exupéry's The Little Prince, Star Trek - The next Generation, The Halleluja Trail (40 Wagen westwärts), The Thief of Bagdad Manche könnte man sich tatsächlich als Diorama ins Zimmer stellen. Manche erkennt man aber auch gleich gar nicht. Logans Run gibt es zweimal. Einmal ohne Movie vornedran und einmal mit.













 1 PunktAdobe Photoshop kann das schon, also das mit dem Entfernen und Ergänzen von Motiven in realen Fotos. Allerdings ist die Adobe Firefly Engine längst nicht so gut wie Midjourney, daher hoffe ich auch dort auf eine solche Möglichkeit. Bzgl. "Fake News" bin ich auch der Meinung, dass es ziemlich sinnlos ist, darüber zu diskutieren. Kommt sowieso. Ich lege meinen Fokus daher mehr auf Aufklärung und Ausbildung, insbesondere auch meinen Kids beizubringen, relevante Nachrichtung zu hinterfragen und zu recherchieren. Zudem fokussiere ich mich wie Du lieber auf den sinnvollen Einsatz von KI als Werkzeug in vielen Bereichen.1 PunktDer fotoforum Verlag hat einen KI Picture Award ins Leben gerufen. Es gibt die drei Kategorien ART, IS IT REAL? und THREE WORDS welche jeweils mit 1.000 Euro für das Siegerbild dotiert sind! Also gleich anmelden und mitmachen ;-)1 PunktDa ich bereits relativ viel probiert habe, würde ich erstmal nur erwähnen womit ich schon Geld gemacht habe. Sind keine großen Beträge da ich noch am "scalen" bin aber hier schonmal eine grobe Auflistung Redbubble + Amazon Merch - Merchandise Fiverr - Logos umsetzen AI Blog - Werbeeinnahmen + Affiliate Etsy - Pattern + Tiles + POD + Custom Zeug Sortiert von Viel nach wenig Einnahmen. Vieles ist noch in der Testphase, mal schauen wo die Reise hingeht.1 Punkt1 PunktMidjourney v5 ist was Fotorealismus angeht aus meiner Sicht aktuell der unangefochtene Primus unter den Bildgeneratoren. Allerdings ist damit auch ein wenig der künstliche und verspielte Charme der Version 4 verloren gegangen. Mit welchen Prompts man diesen mehr oder weniger auch in Version 5 erreichen kann zeige ich Euch hier. Zufällig habe ich heute dazu noch den Parameter --stop entdeckt bzw. erstmalig ausprobiert. Damit könnt Ihr Midjourney mitgeben, dass die Bildgenerierung vorzeitig beendet wird. Das Bild wird also nicht zu 100% generiert, sondern nur bis zu dem via --stop mitgegebenem Prozentsatz, was zu einem nicht perfekten und somit wieder mehr verspieltem Look führt. Prompt: burning scifi spaceship is floating through space, dystopia --ar 3:2 ohne --stop --stop 75 --stop 50 Sehr spannend ist diese Möglichkeit auch bei der Variante --niji, Prompt: anime, manga, spaceship battle --ar 3:2 ohne --stop --stop 75 --stop 50
1 PunktAdobe Photoshop kann das schon, also das mit dem Entfernen und Ergänzen von Motiven in realen Fotos. Allerdings ist die Adobe Firefly Engine längst nicht so gut wie Midjourney, daher hoffe ich auch dort auf eine solche Möglichkeit. Bzgl. "Fake News" bin ich auch der Meinung, dass es ziemlich sinnlos ist, darüber zu diskutieren. Kommt sowieso. Ich lege meinen Fokus daher mehr auf Aufklärung und Ausbildung, insbesondere auch meinen Kids beizubringen, relevante Nachrichtung zu hinterfragen und zu recherchieren. Zudem fokussiere ich mich wie Du lieber auf den sinnvollen Einsatz von KI als Werkzeug in vielen Bereichen.1 PunktDer fotoforum Verlag hat einen KI Picture Award ins Leben gerufen. Es gibt die drei Kategorien ART, IS IT REAL? und THREE WORDS welche jeweils mit 1.000 Euro für das Siegerbild dotiert sind! Also gleich anmelden und mitmachen ;-)1 PunktDa ich bereits relativ viel probiert habe, würde ich erstmal nur erwähnen womit ich schon Geld gemacht habe. Sind keine großen Beträge da ich noch am "scalen" bin aber hier schonmal eine grobe Auflistung Redbubble + Amazon Merch - Merchandise Fiverr - Logos umsetzen AI Blog - Werbeeinnahmen + Affiliate Etsy - Pattern + Tiles + POD + Custom Zeug Sortiert von Viel nach wenig Einnahmen. Vieles ist noch in der Testphase, mal schauen wo die Reise hingeht.1 Punkt1 PunktMidjourney v5 ist was Fotorealismus angeht aus meiner Sicht aktuell der unangefochtene Primus unter den Bildgeneratoren. Allerdings ist damit auch ein wenig der künstliche und verspielte Charme der Version 4 verloren gegangen. Mit welchen Prompts man diesen mehr oder weniger auch in Version 5 erreichen kann zeige ich Euch hier. Zufällig habe ich heute dazu noch den Parameter --stop entdeckt bzw. erstmalig ausprobiert. Damit könnt Ihr Midjourney mitgeben, dass die Bildgenerierung vorzeitig beendet wird. Das Bild wird also nicht zu 100% generiert, sondern nur bis zu dem via --stop mitgegebenem Prozentsatz, was zu einem nicht perfekten und somit wieder mehr verspieltem Look führt. Prompt: burning scifi spaceship is floating through space, dystopia --ar 3:2 ohne --stop --stop 75 --stop 50 Sehr spannend ist diese Möglichkeit auch bei der Variante --niji, Prompt: anime, manga, spaceship battle --ar 3:2 ohne --stop --stop 75 --stop 50




 1 PunktMidjourney ist ein Programm welches auf künstlicher Intelligenz basiert und auf Basis von Text-Eingaben, sogenannten Prompts Bilder (text to image) erzeugt. Diese Bilder werden völlig neu generiert (erstellt, errechnet) und nicht aus anderen Bildern zusammenkopiert. Midjourney ist kein Bildbearbeitungsprogramm. Installation und erste Schritte: Die Installation erfolgt über die kostenlose Kommunikationsplattform Discord, eine eigenständige App ist jedoch in Planung. Bilder werden über den Befehl /imagine gefolgt von dem Prompt und eventuellen Parametern beauftragt. Installation und Bilderstellung sind einfacher, als es auf den ersten Blick erscheint. Preise und Abos: Derzeit gibt es keinen kostenlosen Testaccount mehr, sondern nur noch vier unterschiedliche Abonnements. Ultimative Prompt Tipps: Wer es übrigens nicht abwarten kann bis zum Ende zu lesen, der findet auch hier schon einmal den Link zu den ultimativen Prompt Tipps 😉 Midjourney Parameter: --ar → aspect ratio definiert das Seitenverhältnis wie 3:2, 16:9, 2:3 (ab v5 sind alle Werte möglich) --c → chaos definiert wie sehr das Bildergebnis variiert (Werte von 0 - 100, Standard 0) --q → quality definiert wie detailreich (die Auflösung bleibt gleich!) ein Bild wird. Je höher der Wert ist, desto mehr Rechenzeit wird verbraucht (Werte von 0.25 - 2, Standard 1) --s → stylize definiert wie sehr der Midjourney interne ästhetische Stil angewandt wird. Dieser Stil ist von Version zu Version unterschiedlich. In den /settings kann dieser Wert als low, med, high, very high generell gesetzt oder als Parameter einem Prompt mitgegeben werden (Werte von 0 - 1000, Standard 100) --no → schließt Prompts aus, ein --no plants wird versuchen, dass keine Pflanzen im Bild zu sehen sein werden --r → repeat gibt an, dass ein Job mehrfach generiert wird, --r 3 ergibt drei 4er Variationen (Werte von 1 - 40, Standard 1), funktioniert nur im /fast Modus --seed → Der Midjourney-Bot verwendet eine sogenannte seed Nummer (eine Art Grundrauschen) als Ausgangspunkt für die Erzeugung der Bilder. Die seed Nummer wird für jedes Bild zufällig vergeben. Sie kann nach der Generierung ausgelesen und einem weiteren Auftrag mitgegeben werden, was zu ähnlichen Ergebnissen führt. --stop → beendet die Bildgenerierung zu dem vorgegebenen Prozentwert. Dies führt zu unschärferen, weniger detaillierten und damit künstlerischer angehauchten Ergebnissen (Werte von 0 - 100, Standard 100) --tile → erzeugt Bilder, welche als sich wiederholende Kacheln verwendet werden können, um nahtlose Muster zu erstellen --v → version gibt an, welche Version für das aktuelle Bild genutzt werden soll. Die Version kann in den /settings grundlegend eingestellt wie auch als Parameter einem Prompt mitgegeben werden. Aktuell ist die Version 5.1, insgesamt sind derzeit wählbar: v1, v2, v3, v4, v5, v5a, v5b und v5.1 --style → von den Versionen 4 sowie 5.1 gibt es noch Varianten in der Form von unterschiedlichen Stilen wie --style 4a, --style 4b, --style 4c für die Version 4 und --style raw für die Version 5.1. Letztgenannter wird z.B. über --v 5.1 --style raw gewählt. Zudem gibt es noch unterschiedliche Stile für die niji-Modelle (siehe nächster Punkt) --niji / --niji 5 → “Niji” (ausgesprochen nee-gee) bedeutet auf Japanisch Regenbogen. Es ist spezieller, experimenteller Midjourney-Algorithmus für deutliche verbesserte Anime-Stile und -Bilder. Er ist ein separater, eigenständiger Algorithmus welchen man in den /settings ein- bzw. ausschalten kann oder auch als --niji Parameter einem Prompt mitgeben kann. Für den Modus --niji 5 können zusätzlich noch die Stile (siehe vorheriger Punkt) --style cute, expressive oder scenic mitgegeben werden --iw → image weight gewichtet wie sehr sich Midjourney an einem eigenem, als Vorlage verwendetem Bild/ Foto orientiert (Werte von 0.5 - 2, Standard 1) (siehe dazu auch den Punkt “Eigene Bilder” unter Fortgeschritten) --video → erstellt ein Video der Bildgenerierung --weird → macht die Ergebnisse merkwürdig. Einfach ausprobieren, in bestimmten Fällen kommt man damit warum auch immer zu einem gewünschten Ergebnis. Midjourney Befehle: /blend → damit können bis zu 5 eigene Bilder gemischt, jedoch keine zusätzlichen Prompts mitgegeben werden (wie das funktioniert ist unter dem Punkt “Eigene Bilder” unter Fortgeschritten erklärt) /describe → beschreibt ein hochzuladendes Foto/ Bild in der Form von Prompts. Es werden vier Alternativen angeboten, welche sich dann auch gleich wieder separat generieren und/oder verändern lassen /fast /relax → der fast-Modus generiert die Bilder schnell, wird jedoch auf die kostenpflichtige Rechnerzeit angerechnet. Im relax-Modus (ab dem Standardplan verfügbar) kann die Generierung bis zu 10 Minuten dauern, wird aber nicht auf diese Rechnerzeit angerechnet /info → zeigt die Anzahl der bisherigen Jobs, die verwendete sowie verbleibende Rechnerzeit, das genutzte Abo und weitere Informationen rund um den Account an /settings → zeigt die gewählten, grundsätzlich geltenden Grundeinstellungen des eigenen Midjourney Bots an: Version, Niji-Mode, Stylize Wert, Public-, Fast-, Remix-Mode. Diese Einstellungen können mit jedem Prompt per Parameter aber auch als anderer Wert mitgegeben werden /public /stealth → schaltet zwischen öffentlichem und privatem Modus (ab dem Pro Plan) hin und her /prefer option → Erstellt einen benutzerdefinierten Parameter, mit dem mehrere Prompts sowie Parameter auf einmal an das Ende einer Eingabeaufforderungen angefügt werden können. Dieser wird mit /prefer option set <name des eigenen parameters> <inhalt des eigenen parameters> gebildet /prefer option list → zeigt die benutzerdefinierten Parameter an /prefer suffix → ermöglicht die Mitgabe von mehreren Parametern analog zu /prefer option, erlaubt dabei jedoch nur Parameter und keine Prompts /remix → schaltet den Remix-Modus ein. Damit kann ein Prompt im Rahmen eines Upscalings noch einmal verändert werden /shorten → analysiert Euren Prompt und zeigt an, welche Token (quasi Wörter) mit welcher Gewichtung eine Berücksichtigung finden /tune -> der ab v5.2 nutzbare Style Tuner mit dem man seine ganz eigenen visuellen Styles generieren und auf Bilder anwenden kann Fortgeschrittene Befehle: Eigene Bilder: Midjourney bietet die Möglichkeit, eigene Bilder als Vorlage über die Mitgabe der Bild-URL in einem Prompt als Basis für die Bildgenerierung zu verwenden Multi Prompt: Ein :: nach einem Prompt teilt Midjourney mit, dass dieser Part des Prompts als eigenständiger Text behandelt werden soll: dog biscuit ergibt einen Hundekuchen, dog:: biscuit einen Hund und einen Kuchen Prompt Weight: Mit einem :: und einer zusätzlichen Ziffer können einzelne Prompts gewichtet werden. Dabei können auch negative Ziffern (die Wirkung ist dann analog zu dem --no Parameter) verwendet werden, in Summe müssen die Ziffern jedoch einen positiven Wert ergeben Permutation: Erlaubt die schnelle Generierung von Variationen eines Prompts mit einem einzigen /imagine Befehl (funktioniert nur im /fast Modus). Ein a {red, green, yellow} bird Prompt ergibt drei Jobs, also jeweils vier Variationen eines roten, eines grünen sowie eines gelben Vogels Zoom Out: Mit dem Zoom Out oder auch Outpainting genannt können Bilder am Rand (inhaltlich, nicht von der Auflösung her) erweitert werden. Pan: Mit dem Panning können Bilder in eine Richtung (inhaltlich wie auch von der Auflösung her) erweitert werden. Vary (Region): Mit dem sogenannten Inpainting können Bereiche innerhalb eines Bildes verändert werden. InsightFaceSwap: Ein generiertes Gesicht durch ein Foto-Portrait austauschen. Pro Tipps: Eigenen Discord Server erstellen 8 (ultimative) Prompt Tipps Sinnvoller Promptaufbau Konsistente Bilder Panorama Doppelbelichtung Emoji Prompts Kameraperspektiven ...weitere folgen1 Punkt1 PunktDanke! Sehr guter Hinweis! Ich verfasse heute noch etwas wie „Über AI Imagelab“ und/oder „Erste Schritte“. FAQs gerne bei den jeweiligen Produkten eintragen und „FAQ“ in den Titel nehmen, alternativ als Tag nutzen. Ich bin sowieso dabei, Content aus dem Systemkamera Forum zu übernehmen, da kann ich das zeigen. Definitiv. Mittelfristig jedenfalls… Die nächsten Monate hat das AI Imagelab erstmal „Welpenschutz“, aber langfristig ist das natürlich ein kommerzielles Projekt (wie meine anderen Foren auch). Wenn Du Ideen oder Anregungen hast, gerne her damit – auch per Mail oder PN. Ich würde es gerne bei „Bilder“ belassen, weil einfacher zu verstehen. Auf jeden Fall, immer gerne mehr davon! Gruß Andreas1 Punkt
1 PunktMidjourney ist ein Programm welches auf künstlicher Intelligenz basiert und auf Basis von Text-Eingaben, sogenannten Prompts Bilder (text to image) erzeugt. Diese Bilder werden völlig neu generiert (erstellt, errechnet) und nicht aus anderen Bildern zusammenkopiert. Midjourney ist kein Bildbearbeitungsprogramm. Installation und erste Schritte: Die Installation erfolgt über die kostenlose Kommunikationsplattform Discord, eine eigenständige App ist jedoch in Planung. Bilder werden über den Befehl /imagine gefolgt von dem Prompt und eventuellen Parametern beauftragt. Installation und Bilderstellung sind einfacher, als es auf den ersten Blick erscheint. Preise und Abos: Derzeit gibt es keinen kostenlosen Testaccount mehr, sondern nur noch vier unterschiedliche Abonnements. Ultimative Prompt Tipps: Wer es übrigens nicht abwarten kann bis zum Ende zu lesen, der findet auch hier schon einmal den Link zu den ultimativen Prompt Tipps 😉 Midjourney Parameter: --ar → aspect ratio definiert das Seitenverhältnis wie 3:2, 16:9, 2:3 (ab v5 sind alle Werte möglich) --c → chaos definiert wie sehr das Bildergebnis variiert (Werte von 0 - 100, Standard 0) --q → quality definiert wie detailreich (die Auflösung bleibt gleich!) ein Bild wird. Je höher der Wert ist, desto mehr Rechenzeit wird verbraucht (Werte von 0.25 - 2, Standard 1) --s → stylize definiert wie sehr der Midjourney interne ästhetische Stil angewandt wird. Dieser Stil ist von Version zu Version unterschiedlich. In den /settings kann dieser Wert als low, med, high, very high generell gesetzt oder als Parameter einem Prompt mitgegeben werden (Werte von 0 - 1000, Standard 100) --no → schließt Prompts aus, ein --no plants wird versuchen, dass keine Pflanzen im Bild zu sehen sein werden --r → repeat gibt an, dass ein Job mehrfach generiert wird, --r 3 ergibt drei 4er Variationen (Werte von 1 - 40, Standard 1), funktioniert nur im /fast Modus --seed → Der Midjourney-Bot verwendet eine sogenannte seed Nummer (eine Art Grundrauschen) als Ausgangspunkt für die Erzeugung der Bilder. Die seed Nummer wird für jedes Bild zufällig vergeben. Sie kann nach der Generierung ausgelesen und einem weiteren Auftrag mitgegeben werden, was zu ähnlichen Ergebnissen führt. --stop → beendet die Bildgenerierung zu dem vorgegebenen Prozentwert. Dies führt zu unschärferen, weniger detaillierten und damit künstlerischer angehauchten Ergebnissen (Werte von 0 - 100, Standard 100) --tile → erzeugt Bilder, welche als sich wiederholende Kacheln verwendet werden können, um nahtlose Muster zu erstellen --v → version gibt an, welche Version für das aktuelle Bild genutzt werden soll. Die Version kann in den /settings grundlegend eingestellt wie auch als Parameter einem Prompt mitgegeben werden. Aktuell ist die Version 5.1, insgesamt sind derzeit wählbar: v1, v2, v3, v4, v5, v5a, v5b und v5.1 --style → von den Versionen 4 sowie 5.1 gibt es noch Varianten in der Form von unterschiedlichen Stilen wie --style 4a, --style 4b, --style 4c für die Version 4 und --style raw für die Version 5.1. Letztgenannter wird z.B. über --v 5.1 --style raw gewählt. Zudem gibt es noch unterschiedliche Stile für die niji-Modelle (siehe nächster Punkt) --niji / --niji 5 → “Niji” (ausgesprochen nee-gee) bedeutet auf Japanisch Regenbogen. Es ist spezieller, experimenteller Midjourney-Algorithmus für deutliche verbesserte Anime-Stile und -Bilder. Er ist ein separater, eigenständiger Algorithmus welchen man in den /settings ein- bzw. ausschalten kann oder auch als --niji Parameter einem Prompt mitgeben kann. Für den Modus --niji 5 können zusätzlich noch die Stile (siehe vorheriger Punkt) --style cute, expressive oder scenic mitgegeben werden --iw → image weight gewichtet wie sehr sich Midjourney an einem eigenem, als Vorlage verwendetem Bild/ Foto orientiert (Werte von 0.5 - 2, Standard 1) (siehe dazu auch den Punkt “Eigene Bilder” unter Fortgeschritten) --video → erstellt ein Video der Bildgenerierung --weird → macht die Ergebnisse merkwürdig. Einfach ausprobieren, in bestimmten Fällen kommt man damit warum auch immer zu einem gewünschten Ergebnis. Midjourney Befehle: /blend → damit können bis zu 5 eigene Bilder gemischt, jedoch keine zusätzlichen Prompts mitgegeben werden (wie das funktioniert ist unter dem Punkt “Eigene Bilder” unter Fortgeschritten erklärt) /describe → beschreibt ein hochzuladendes Foto/ Bild in der Form von Prompts. Es werden vier Alternativen angeboten, welche sich dann auch gleich wieder separat generieren und/oder verändern lassen /fast /relax → der fast-Modus generiert die Bilder schnell, wird jedoch auf die kostenpflichtige Rechnerzeit angerechnet. Im relax-Modus (ab dem Standardplan verfügbar) kann die Generierung bis zu 10 Minuten dauern, wird aber nicht auf diese Rechnerzeit angerechnet /info → zeigt die Anzahl der bisherigen Jobs, die verwendete sowie verbleibende Rechnerzeit, das genutzte Abo und weitere Informationen rund um den Account an /settings → zeigt die gewählten, grundsätzlich geltenden Grundeinstellungen des eigenen Midjourney Bots an: Version, Niji-Mode, Stylize Wert, Public-, Fast-, Remix-Mode. Diese Einstellungen können mit jedem Prompt per Parameter aber auch als anderer Wert mitgegeben werden /public /stealth → schaltet zwischen öffentlichem und privatem Modus (ab dem Pro Plan) hin und her /prefer option → Erstellt einen benutzerdefinierten Parameter, mit dem mehrere Prompts sowie Parameter auf einmal an das Ende einer Eingabeaufforderungen angefügt werden können. Dieser wird mit /prefer option set <name des eigenen parameters> <inhalt des eigenen parameters> gebildet /prefer option list → zeigt die benutzerdefinierten Parameter an /prefer suffix → ermöglicht die Mitgabe von mehreren Parametern analog zu /prefer option, erlaubt dabei jedoch nur Parameter und keine Prompts /remix → schaltet den Remix-Modus ein. Damit kann ein Prompt im Rahmen eines Upscalings noch einmal verändert werden /shorten → analysiert Euren Prompt und zeigt an, welche Token (quasi Wörter) mit welcher Gewichtung eine Berücksichtigung finden /tune -> der ab v5.2 nutzbare Style Tuner mit dem man seine ganz eigenen visuellen Styles generieren und auf Bilder anwenden kann Fortgeschrittene Befehle: Eigene Bilder: Midjourney bietet die Möglichkeit, eigene Bilder als Vorlage über die Mitgabe der Bild-URL in einem Prompt als Basis für die Bildgenerierung zu verwenden Multi Prompt: Ein :: nach einem Prompt teilt Midjourney mit, dass dieser Part des Prompts als eigenständiger Text behandelt werden soll: dog biscuit ergibt einen Hundekuchen, dog:: biscuit einen Hund und einen Kuchen Prompt Weight: Mit einem :: und einer zusätzlichen Ziffer können einzelne Prompts gewichtet werden. Dabei können auch negative Ziffern (die Wirkung ist dann analog zu dem --no Parameter) verwendet werden, in Summe müssen die Ziffern jedoch einen positiven Wert ergeben Permutation: Erlaubt die schnelle Generierung von Variationen eines Prompts mit einem einzigen /imagine Befehl (funktioniert nur im /fast Modus). Ein a {red, green, yellow} bird Prompt ergibt drei Jobs, also jeweils vier Variationen eines roten, eines grünen sowie eines gelben Vogels Zoom Out: Mit dem Zoom Out oder auch Outpainting genannt können Bilder am Rand (inhaltlich, nicht von der Auflösung her) erweitert werden. Pan: Mit dem Panning können Bilder in eine Richtung (inhaltlich wie auch von der Auflösung her) erweitert werden. Vary (Region): Mit dem sogenannten Inpainting können Bereiche innerhalb eines Bildes verändert werden. InsightFaceSwap: Ein generiertes Gesicht durch ein Foto-Portrait austauschen. Pro Tipps: Eigenen Discord Server erstellen 8 (ultimative) Prompt Tipps Sinnvoller Promptaufbau Konsistente Bilder Panorama Doppelbelichtung Emoji Prompts Kameraperspektiven ...weitere folgen1 Punkt1 PunktDanke! Sehr guter Hinweis! Ich verfasse heute noch etwas wie „Über AI Imagelab“ und/oder „Erste Schritte“. FAQs gerne bei den jeweiligen Produkten eintragen und „FAQ“ in den Titel nehmen, alternativ als Tag nutzen. Ich bin sowieso dabei, Content aus dem Systemkamera Forum zu übernehmen, da kann ich das zeigen. Definitiv. Mittelfristig jedenfalls… Die nächsten Monate hat das AI Imagelab erstmal „Welpenschutz“, aber langfristig ist das natürlich ein kommerzielles Projekt (wie meine anderen Foren auch). Wenn Du Ideen oder Anregungen hast, gerne her damit – auch per Mail oder PN. Ich würde es gerne bei „Bilder“ belassen, weil einfacher zu verstehen. Auf jeden Fall, immer gerne mehr davon! Gruß Andreas1 Punkt

































































.jpg.e8e7d80af04843577f1fe78ad4f05aab.jpg)


























































































Account
Suche
Configure browser push notifications
Chrome (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions → Notifications.
- Adjust your preference.
Chrome (Desktop)
- Click the padlock icon in the address bar.
- Select Site settings.
- Find Notifications and adjust your preference.
Safari (iOS 16.4+)
- Ensure the site is installed via Add to Home Screen.
- Open Settings App → Notifications.
- Find your app name and adjust your preference.
Safari (macOS)
- Go to Safari → Preferences.
- Click the Websites tab.
- Select Notifications in the sidebar.
- Find this website and adjust your preference.
Edge (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions.
- Find Notifications and adjust your preference.
Edge (Desktop)
- Click the padlock icon in the address bar.
- Click Permissions for this site.
- Find Notifications and adjust your preference.
Firefox (Android)
- Go to Settings → Site permissions.
- Tap Notifications.
- Find this site in the list and adjust your preference.
Firefox (Desktop)
- Open Firefox Settings.
- Search for Notifications.
- Find this site in the list and adjust your preference.